Chroma 向量数据库架构详解
引言
Chroma 是一个开源的向量数据库,专为存储和检索向量嵌入而设计。最近学习了相关细节,在此记录。
1、从一个 Query 流程说起:
1.1一个文档从 RAG 进入 Chroma 流程如下:
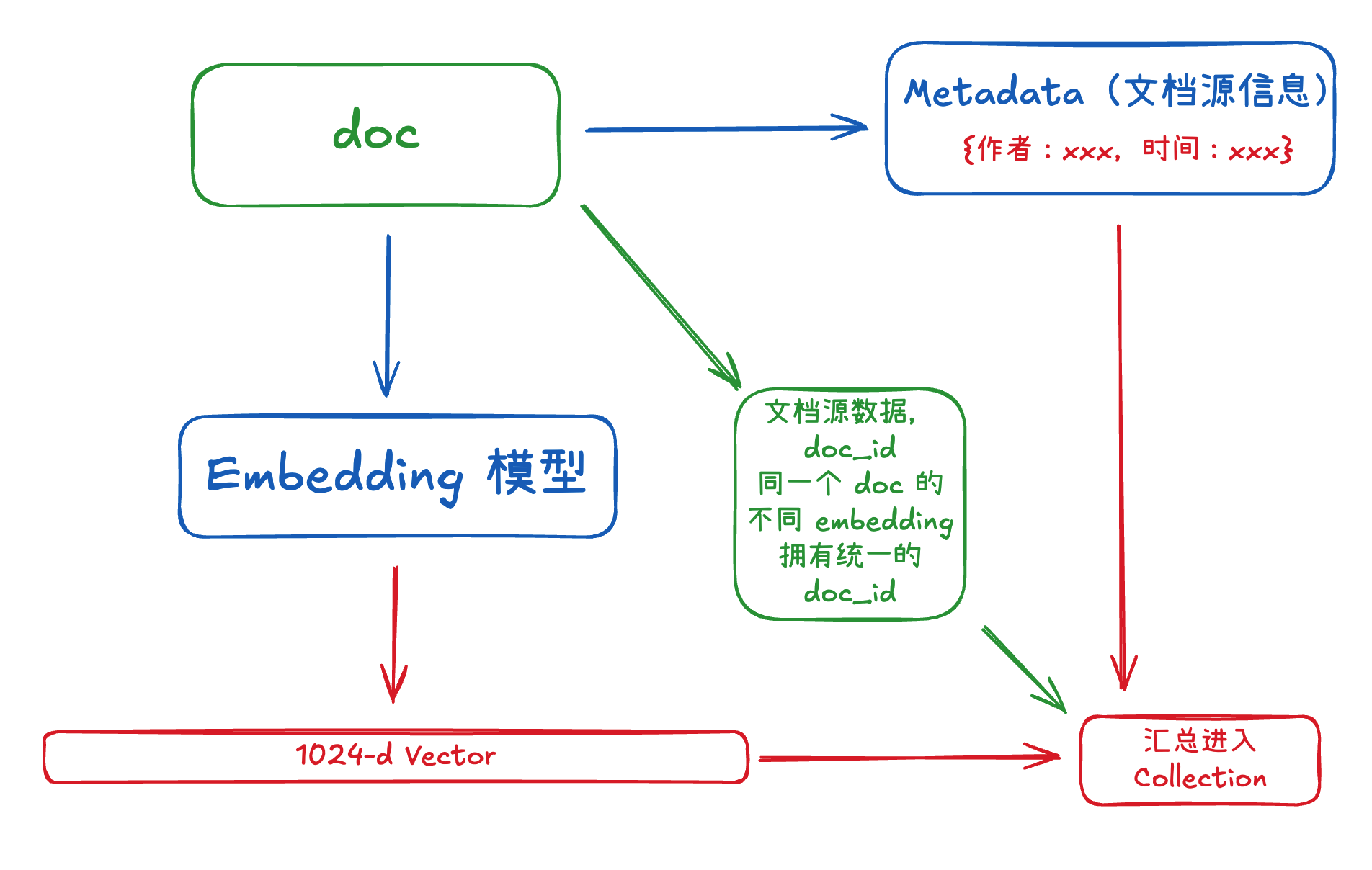
代码:
xxxxxxxxxx
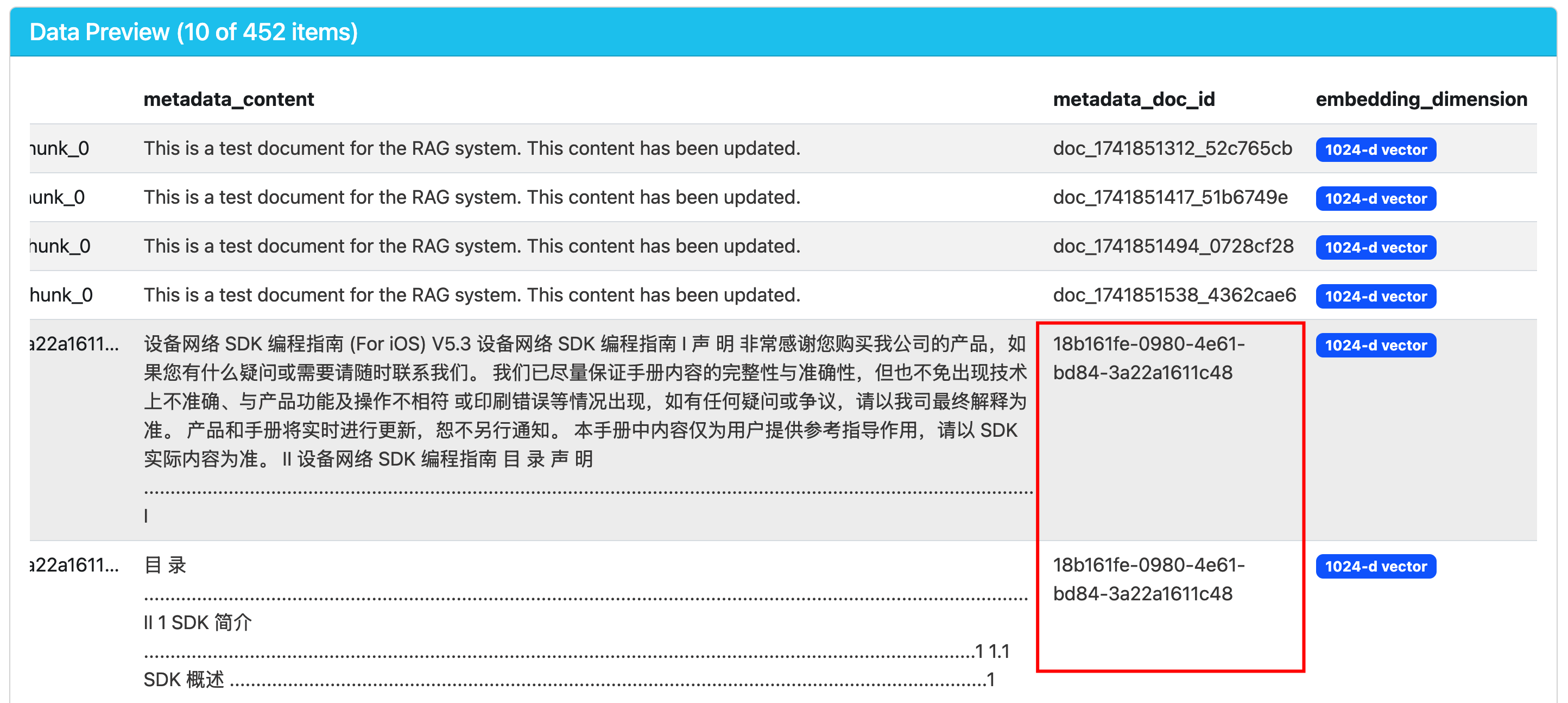
collection.add( ids=ids, embeddings=embeddings, metadatas=metadatas, documents=ids # 使用 ID 作为 document )同一个文档的不同 chunks,属于同一个 doc_id:
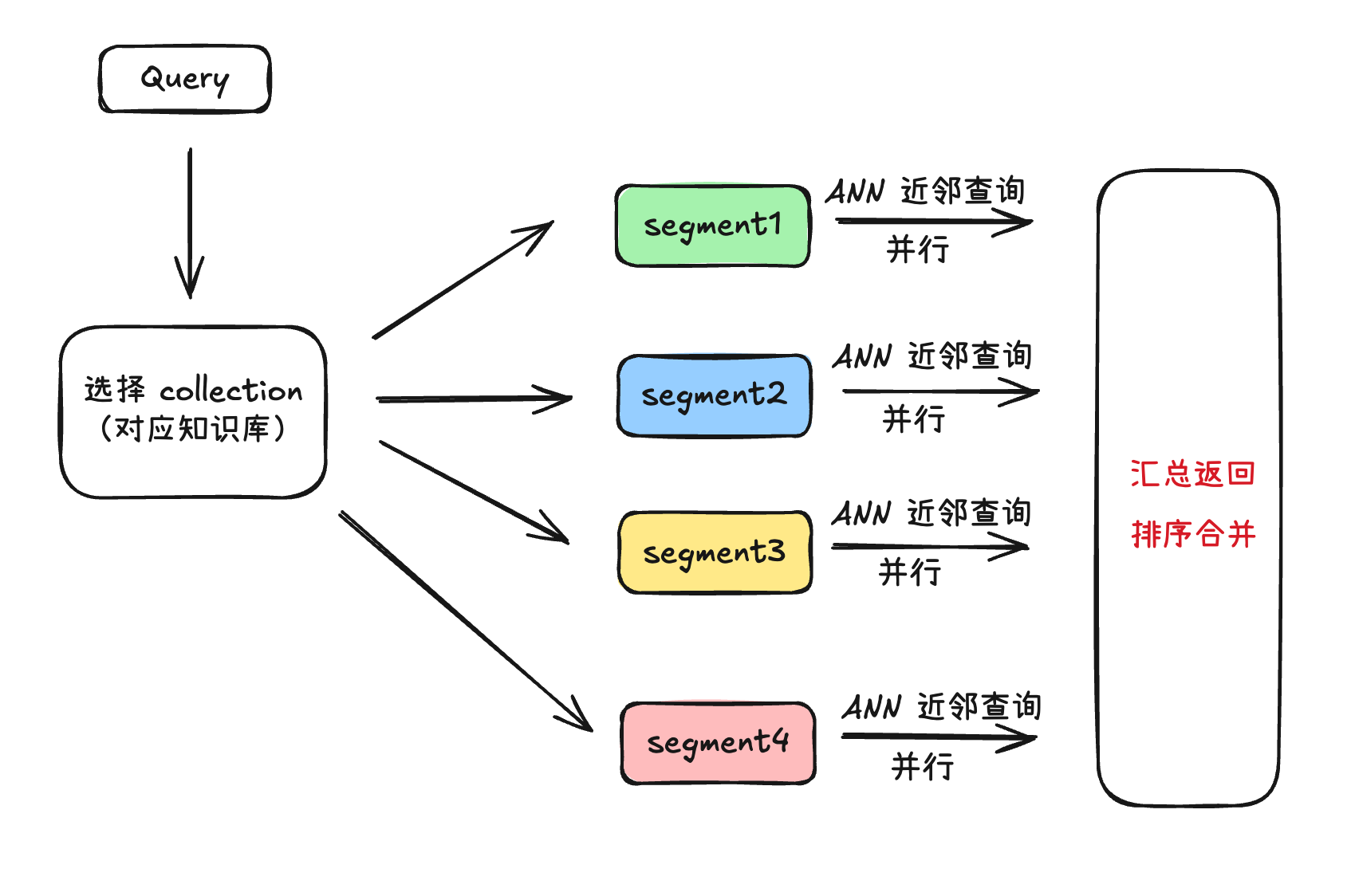
1.2一个问题从 RAG 进到数据库查询流程如下:
a、选择对应知识库内容
b、Collection 下不同的 seg 分配着不同的内容,一个 Collection 下有着多个 seg,支持并行查询,快速返回
c、所有 seg 查询完毕交由 Collection 汇总返回给 RAG。
2、核心架构组件
Collection 和 Segment
Collection 是 Chroma 中的高级抽象,类似于传统数据库中的表。它是相关数据的逻辑集合,包含:
文档/数据
这些文档的向量嵌入
可选的元数据
Segment 是 Collection 内部的底层存储单元。一个 Collection 通常由多个 Segment 组成,这种设计使得 Chroma 能够:
并行处理查询
分散存储负载
提高整体性能
区别:Collection 是面向用户的逻辑单元,而 Segment 是内部实现细节,用于实际存储数据并处理查询。
其他重要组件
除了 Collection 和 Segment,Chroma 还包含以下关键组件:
Embedder (嵌入器):负责将原始数据转换为向量表示
Storage Backend (存储后端):管理数据的持久化
Index (索引):加速向量搜索的数据结构,默认使用 HNSW
API Layer (API 层):提供与 Chroma 交互的接口
Hnsw (层次导航小世界图):默认的近似最近邻搜索算法
文档结构
在 Chroma 中,每个文档由三个主要部分组成:
文档内容(Document):原始的文本、图像或其他类型的数据
向量嵌入(Embedding):文档内容通过嵌入模型转换成的向量表示
元数据(Metadata):关于文档的附加信息,以键值对形式存储(比如创建时间,作者等信息)
每个记录还有一个唯一标识符(doc_id) 不同的 embedding,如果属于同一个 doc,则共用一个 doc_id。
以上