基于ViT 特征映射和解码器的多模态大模型实验
Author:张一极
date: 2025年07月05日21:07:49
近期实现了一个基于ViT 和Transformer解码器的端到端OCR模型,通过一个特征映射层加文本解码,给原本用于图像的模型增加了多模态的能力尝试,测试用于识别包含数字、字母和特殊字符的文本图像。在8534个样本的测试集上达到了97.47%的字符级准确率和96.25%的序列级准确率。
1.整体架构设计
参数数量大约1个亿,总体训练时间可控。
如下图,总体为编码器-解码器架构:
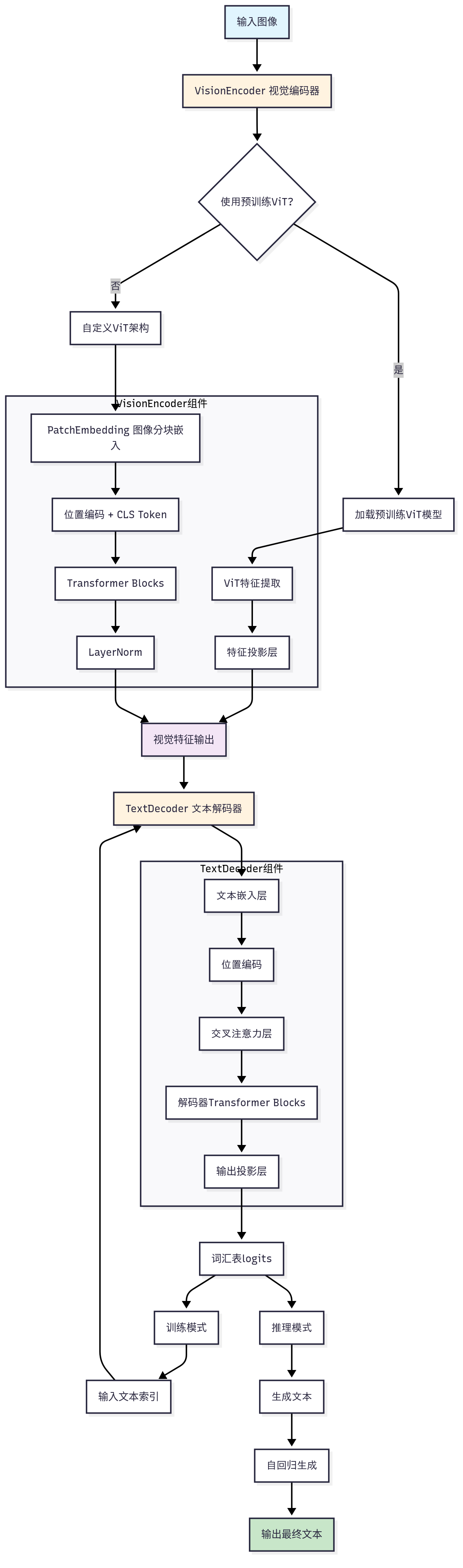
核心组件
1. 视觉编码器 (VisionEncoder)
预训练ViT主干网络
使用基础预训练ViT模型,前两轮不做参数调整
配置:
vit_base_patch16_224输入:224×224×3 RGB图像
输出:197个patch tokens (196个图像patch + 1个CLS token)
特征维度:768维
xxxxxxxxxx# 核心实现self.vit = timm.create_model( config.pretrained_vit_model, pretrained=True, num_classes=0, # 移除分类头 global_pool='', # 保留所有patch token img_size=config.image_size)特征投影层
当预训练ViT特征维度与配置不匹配时启用(确保维度相融)
确保特征维度一致性:
Linear(vit_feature_dim, hidden_dim)
2. 文本解码器 (TextDecoder)
文本嵌入层
字符嵌入:
Embedding(vocab_size, hidden_dim)位置嵌入:
Embedding(max_seq_length, hidden_dim)词汇表大小:N个字符(来自数据集,包括特殊token)
交叉注意力模块 (CrossAttention)
多模态任务需要,专门处理视觉-文本交互,其实就是一个特征映射
Query来自文本,Key/Value来自视觉特征
实现视觉引导的文本生成
xxxxxxxxxxclass CrossAttention(nn.Module): def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.): super().__init__() self.q = nn.Linear(dim, dim, bias=qkv_bias) self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias) # ... 其他组件 def forward(self, query, key_value): # query: [B, N_q, C] - 文本序列 # key_value: [B, N_kv, C] - 视觉特征 # 计算注意力权重并融合信息自注意力解码器块
6层TransformerBlock(num_layers // 2)
每层包含多头自注意力、前馈网络和层归一化
使用因果掩码(causal mask)确保自回归生成,其实就是一个上三角mask,只允许访问到当前位置的内容,后续不允许看到,为了锻炼模型的自回归能力。
3. 基础组件 (VIT自带)
多头注意力机制 (MultiHeadAttention)
标准的多头注意力实现
支持掩码机制
可配置注意力头数(默认12个)
Transformer块 (TransformerBlock)
包含自注意力、前馈网络
残差连接和层归一化
支持dropout正则化
2.训练策略
1. 分阶段训练策略
阶段1:冻结ViT参数(前2个epoch)如果前期不冻结,后续很难收敛
只训练文本解码器部分
让模型先学会基本的文本生成能力
避免预训练特征被破坏
阶段2:端到端训练(第3个epoch开始)
解冻ViT参数
使用计划采样进行完整训练
优化整个模型的性能
xxxxxxxxxx# 训练过程中的参数冻结控制if config.use_pretrained and epoch == config.freeze_vit_epochs: model.vision_encoder.unfreeze_vit()2. 计划采样 (Scheduled Sampling)**
传统的Teacher Forcing在训练时使用真实标签,但在推理时使用模型预测,导致训练-推理差异(暴露偏差)。如果强制teacher force全程,则容易出现后续模型的acc很高,但是推理过程不断循环,或者很早输出EOS的情况。
目前我的解决方案:
动态调整教师强制比率
早期训练主要使用真实标签(模型自身输出作为输入)
指数衰减策略:
teacher_forcing_ratio = min_prob + (1 - min_prob) * decay_rate^epoch
xxxxxxxxxxdef get_scheduled_sampling_prob(epoch, config): if epoch < config.scheduled_sampling_start_epoch: return 1.0 if config.scheduled_sampling_decay_type == 'exponential': decay = config.scheduled_sampling_decay_rate ** (epoch - config.scheduled_sampling_start_epoch + 1) else: # linear decay = 1.0 - (epoch - config.scheduled_sampling_start_epoch + 1) * config.scheduled_sampling_decay_rate return max(config.scheduled_sampling_min_prob, decay)3. 训练配置
模型参数
隐藏层维度:768
注意力头数:12
层数:12(编码器)+ 6(解码器)
最大序列长度:20
Dropout率:0.1
训练参数
批次大小:48
学习率:1e-4
优化器:AdamW + 权重衰减0.01
学习率调度:余弦退火
梯度裁剪:1.0
数据增强无
模型训练指标:
损失函数:CrossEntropyLoss(忽略填充的PAD token)
准确率指标:字符级准确率、序列级准确率
验证策略:90%训练集 + 10%验证集
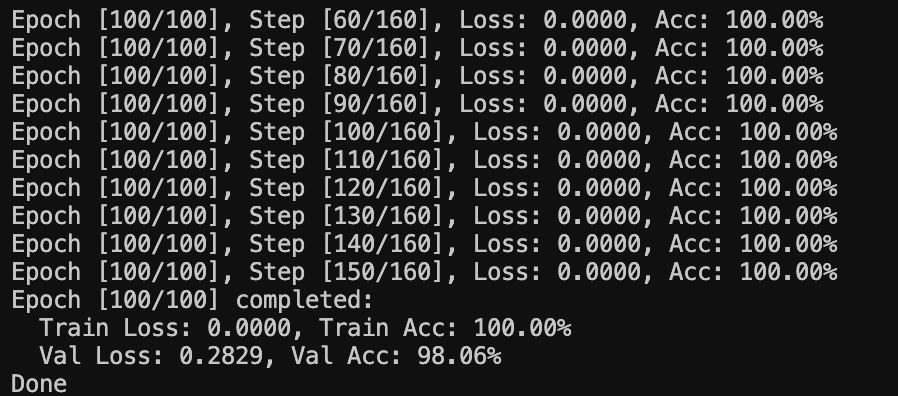
最后acc: Train Loss: 0.0000, Train Acc: 100.00% Val Loss: 0.2829, Val Acc: 98.06%(最后阶段使用的是模型自输出作为上一个tokens)
3.模型实现代码
x
import torchimport torch.nn as nnfrom .encoder import VisionEncoderfrom .decoder import TextDecoderclass MModel(nn.Module):"""模型主类"""def __init__(self, config):super().__init__()self.config = configself.vision_encoder = VisionEncoder(config)self.text_decoder = TextDecoder(config)def forward(self, images, text_indices=None):visual_features = self.vision_encoder(images)if text_indices is not None:logits = self.text_decoder(text_indices, visual_features)return logitselse:return self.generate(visual_features)def generate(self, visual_features, max_length=100):B = visual_features.shape[0]device = visual_features.devicegenerated = torch.full((B, 1), self.config.char_to_idx['<SOS>'], device=device)for _ in range(max_length - 1):logits = self.text_decoder(generated, visual_features)next_token = logits[:, -1, :].argmax(dim=-1, keepdim=True)generated = torch.cat([generated, next_token], dim=1)if (next_token == self.config.char_to_idx['<EOS>']).all():breakreturn generated所以理论上,一个大的基础模型,加上特征映射以后,可以接上任意一个后处理解码器,去处理不同多模态任务。
以上