Transformer
author:张一极
transformer在英文里的直译是一切与变化有关的载体,比如变形金刚,变压器之类的变换工具,在机器学习里面,初次提出这个思路的是paper:attention is all you need,在多任务取得sota后,transformer在多个领域开花,X-fromers层出不穷,transformer的核心组件即self-attention layer,最初用于seq2seq网络中。
我们知道,seq2seq可以通过rnn制造出多输入和多输出网络,如果要替换掉rnn的部分,但是rnn网络有个缺点:假如输入是一个长序列的seq,rnn只能关注到上下文的信息,无法关注到句首句尾的global信息,因为rnn只接收上一级的输出作为额外输入,当然了可能他包含了开头带来的影响,但是他没带来的是后面部分的带来的影响,也就是他的attention只有当前所在位置的前面部分seq内容会被注意到,后面的直接被忽略了,并且经过多级递减后,前面的attention带来的影响已经被压缩到很小,并且rnn无法被并行加速,因为他的每一个输入都必须有前一个输出作为额外输入。于是attention应运而生,一个可以并行化的layer,并且照顾到整个seq的视野,使用cnn作为实现的layer。
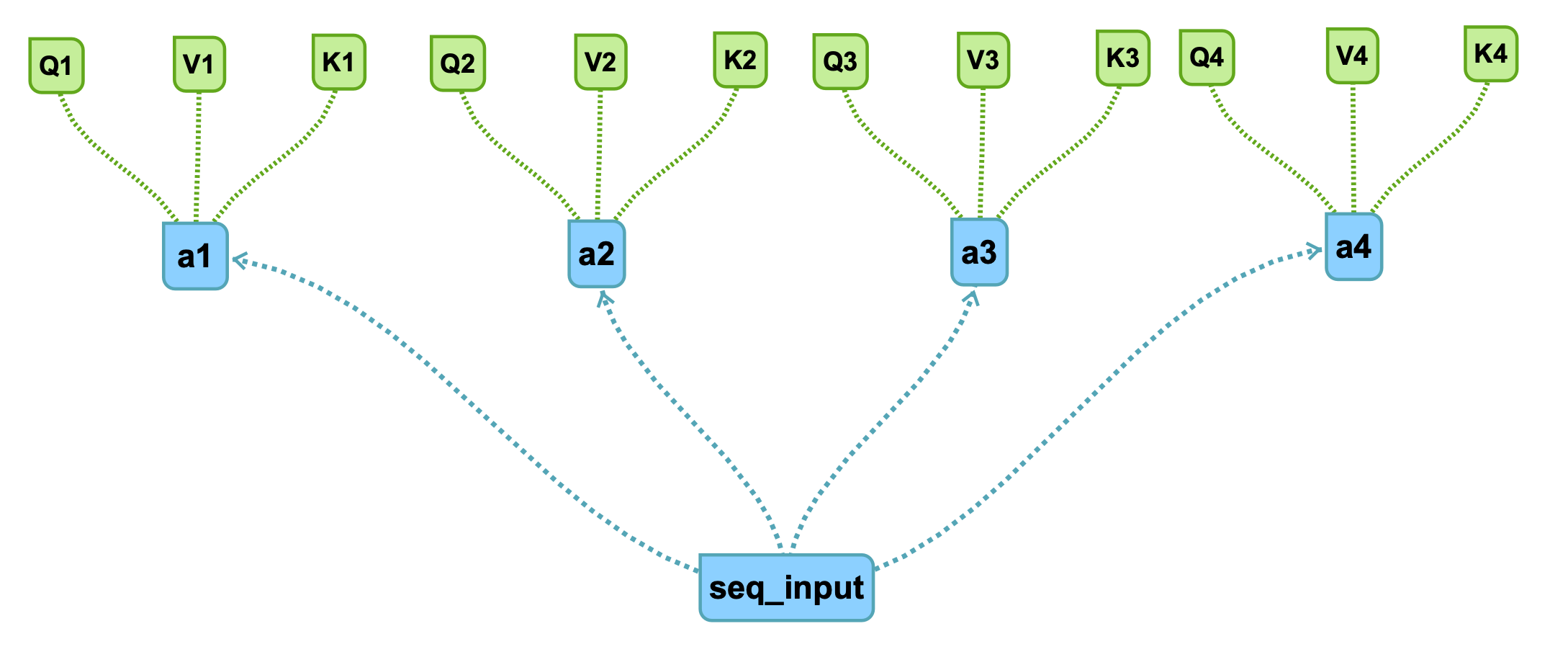
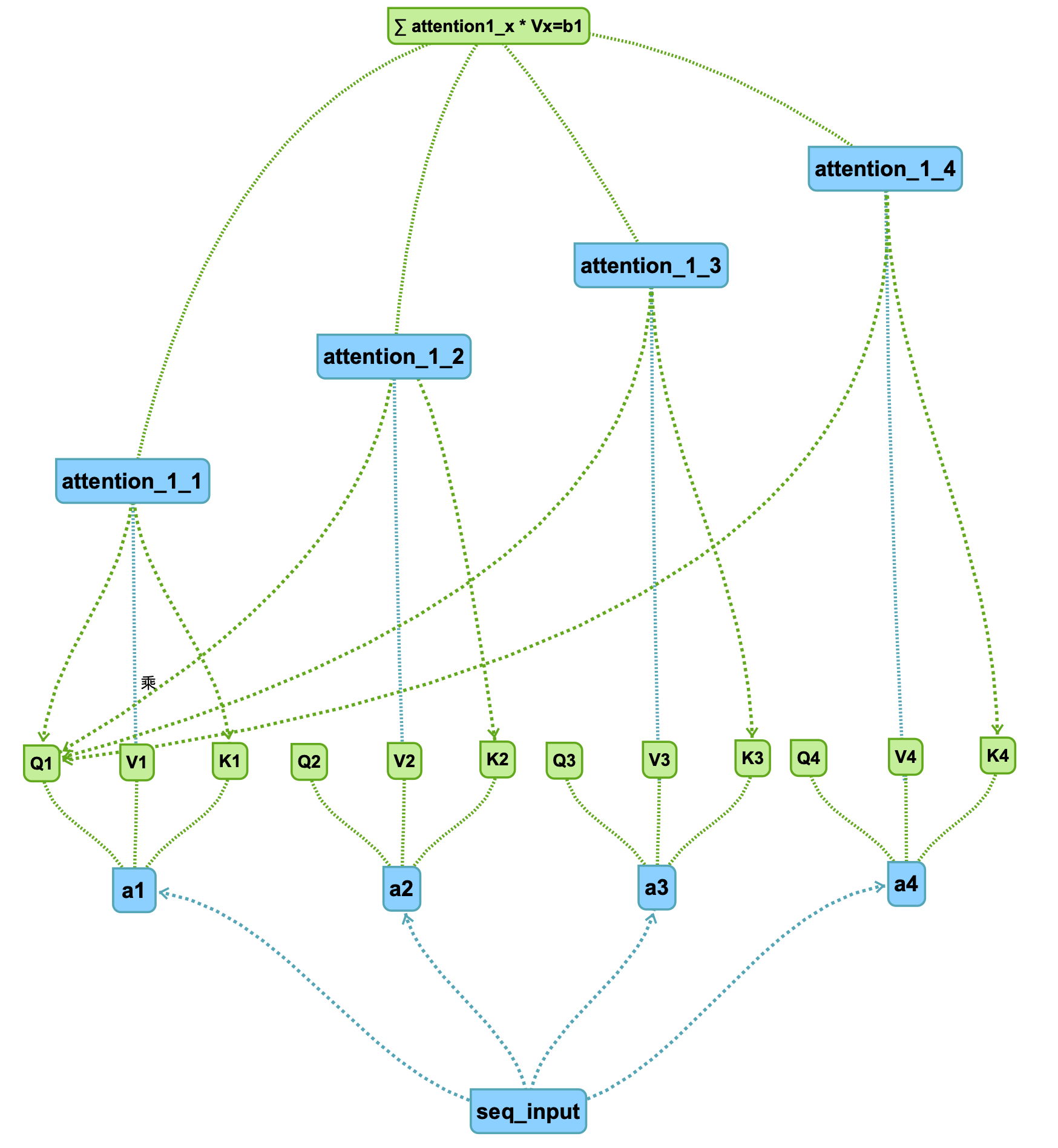
attention的核心在于,分成了三个矩阵,在这里,我使用代表第一部分的seq输入,首先生成第一个q代表,,假设把seq分为四部分输入,分别为,其他同理。
得到三个矩阵,Q,K,V,分别意味着主要比较部分Q,K关键词(暂时理解),V(额外信息)。
四个部分得到十二个矩阵:
接下来,attention的处理步骤是对,针对每一个key做attention,即通过这两个向量得到一个score输出:
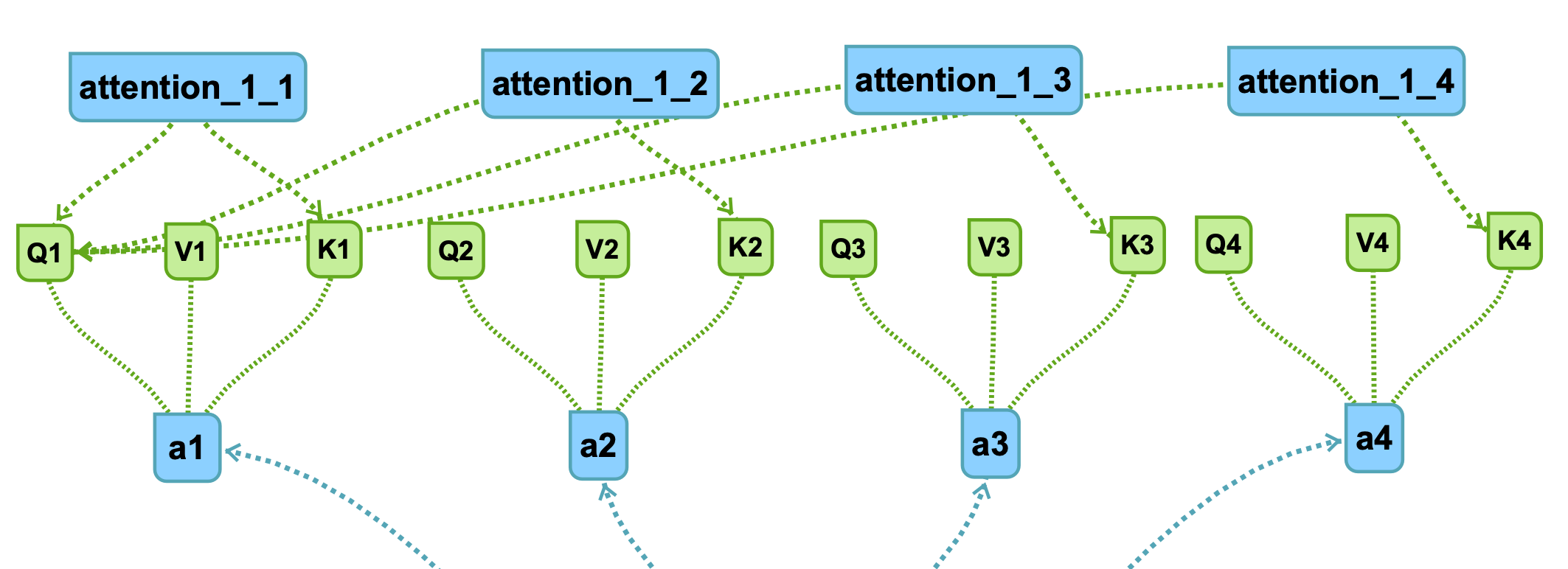
对于每个Q都采取一样的操作,可以得到四组十六个attention结果:
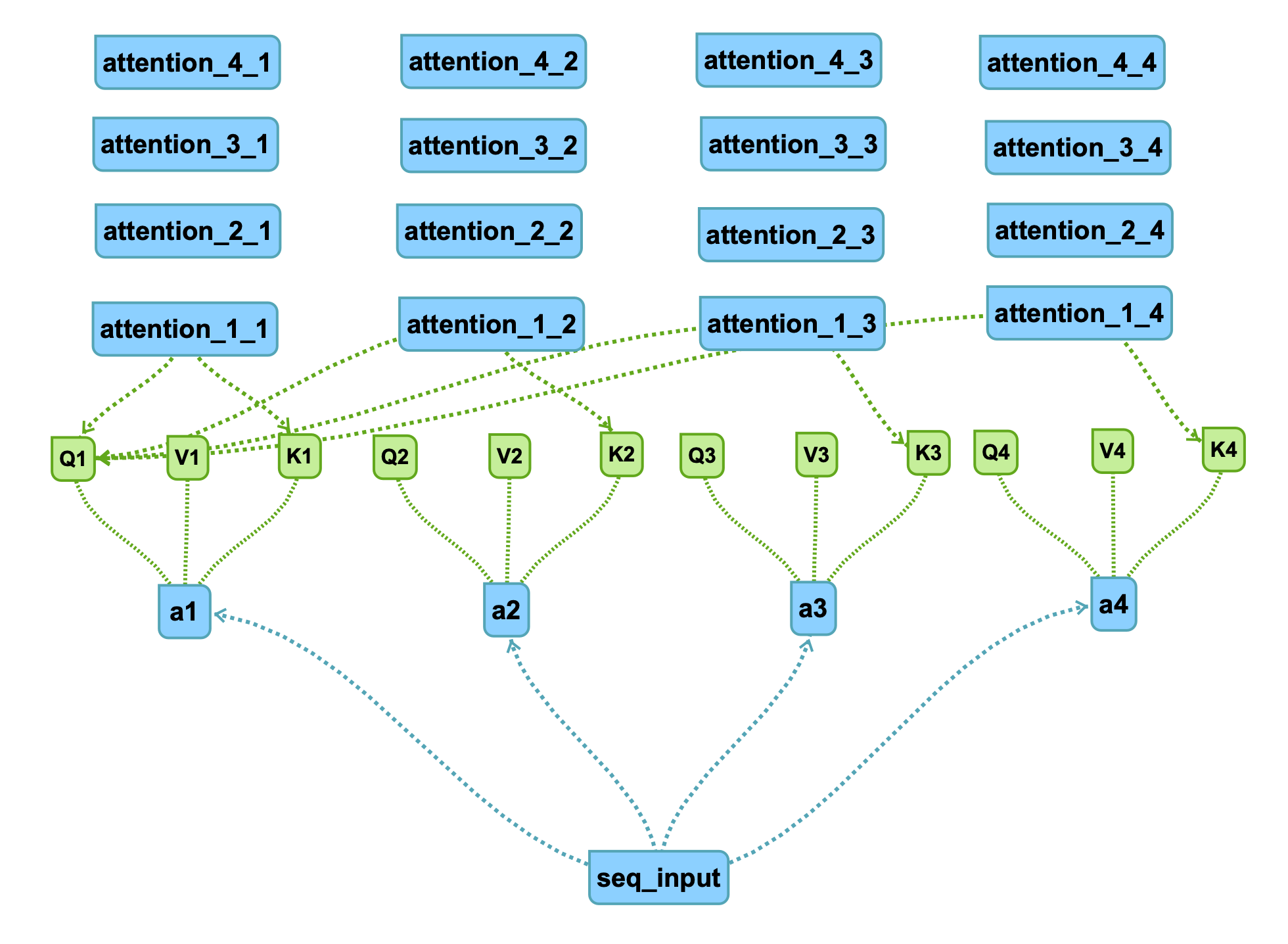
具体的连线根据q1可知,不再赘述。
比如attention_2_3代表q2和k3进行attention得到score。
设得到的attention为,十六个后面接入softmax函数进行压缩,得到,在点乘以V(额外信息加成)
即:
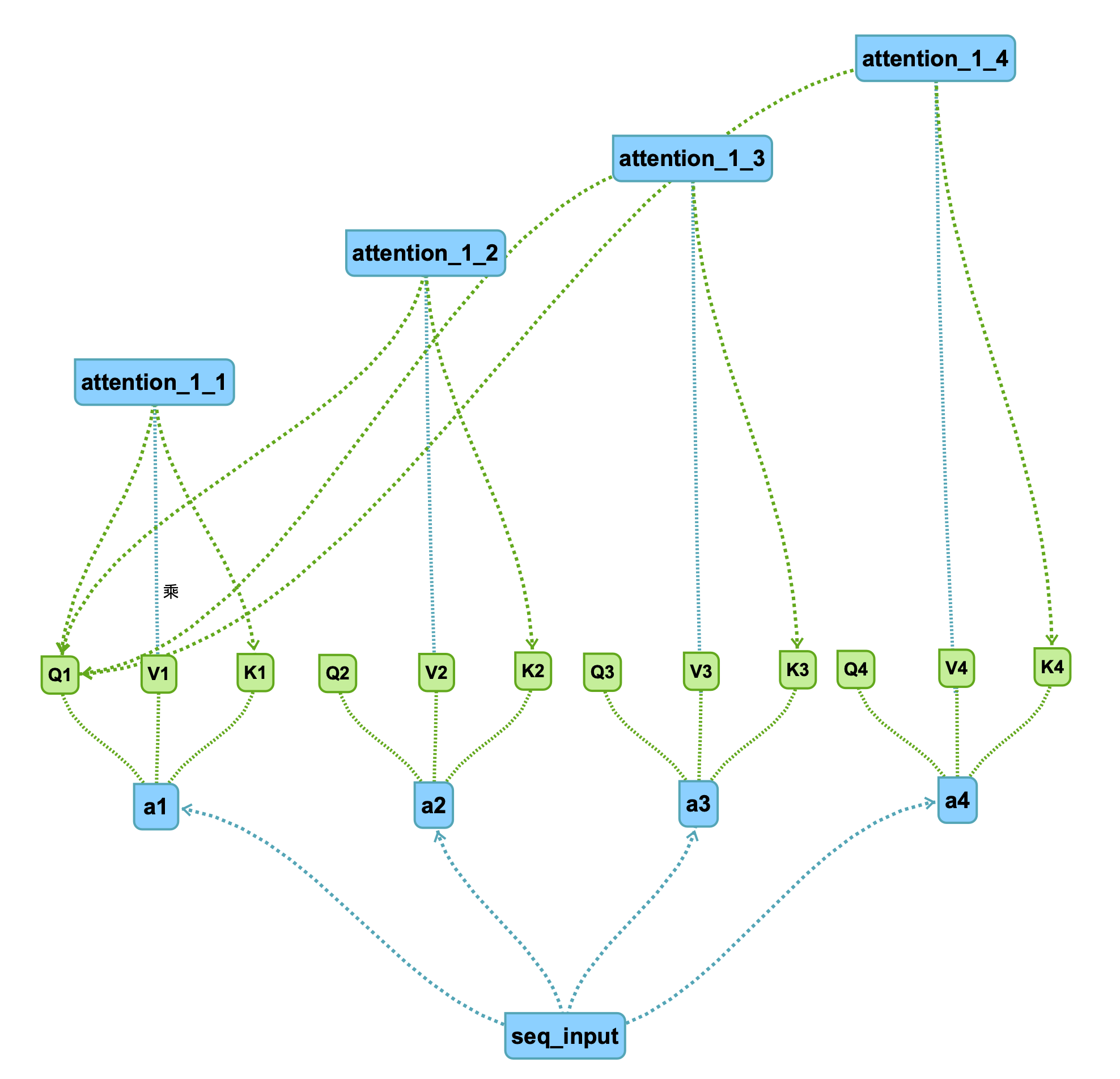
注:这里的attention为softmax输出后的,蓝线带乘积,得到最终的attention结果,图中累加得到。
以此类推。
所以,通过self-attention layer,也可以实现rnn类似的seq2seq的输入输出效果,并且能用cnn的感受野特点去照顾到所有的seq片段,并且这里面所有操作都可以成功组成矩阵乘法,很方便使用gpu加速。
矩阵化加速
attention的矩阵化可以理解为k矩阵与q矩阵的内积:
再经softmax得到
得到的输出:
以上。
time:18:47