Alex遇到的一个问题
网络结构如图的情况下:
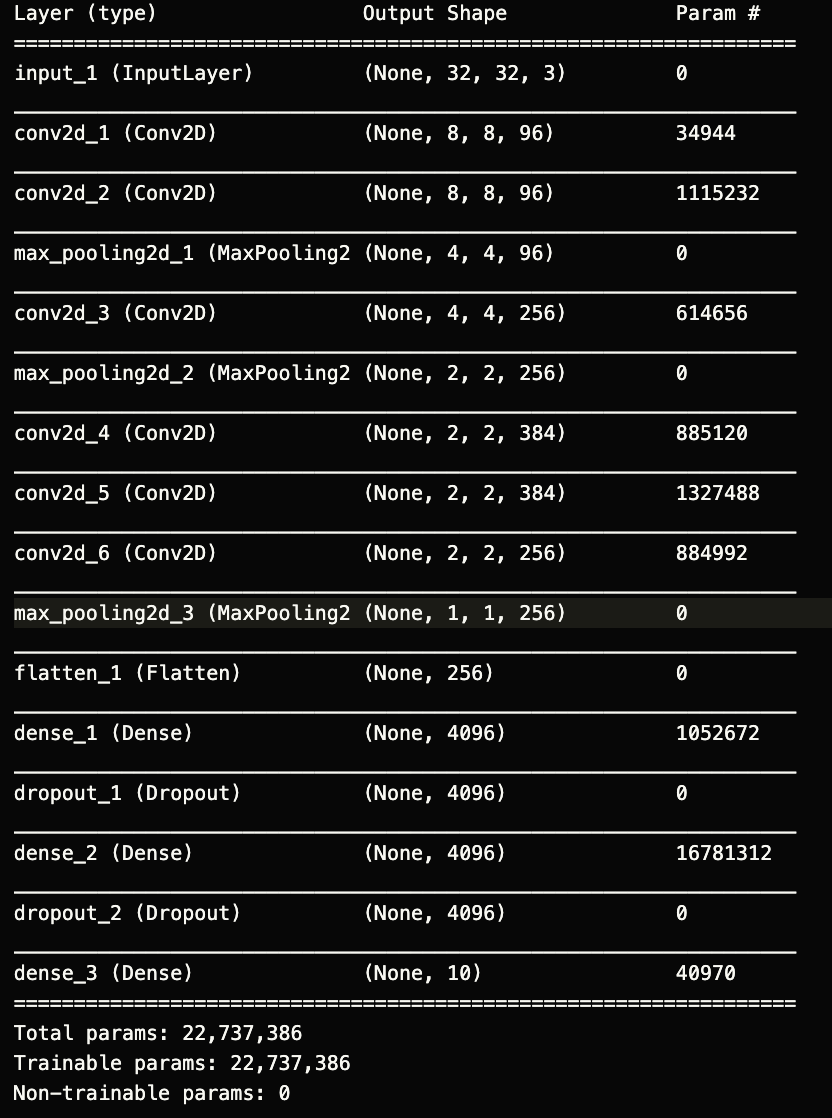
同一套代码,跑出了两个极端的base,目前发现是前向传播的矩阵输出都一样,导致的梯度消失问题,
日中log如下:
xxxxxxxxxx531input:tensor([[[[0.4902, 0.4314, 0.4000, ..., 0.7922, 0.7843, 0.7922],2[0.5569, 0.5725, 0.6902, ..., 0.7647, 0.7765, 0.8000],3[0.7059, 0.5608, 0.6118, ..., 0.4784, 0.5451, 0.6196],4...,5[0.4078, 0.3961, 0.3961, ..., 0.4941, 0.4941, 0.4902],6[0.4078, 0.4118, 0.4275, ..., 0.5412, 0.5373, 0.5373],7[0.4118, 0.4235, 0.4510, ..., 0.5608, 0.5608, 0.5647]],8[[0.4902, 0.3961, 0.3529, ..., 0.8118, 0.8039, 0.8157],9[0.5725, 0.5647, 0.6745, ..., 0.7882, 0.8039, 0.8275],10[0.7255, 0.5725, 0.6157, ..., 0.4353, 0.5020, 0.5765],11...,12[0.3216, 0.3137, 0.3176, ..., 0.4039, 0.4039, 0.3961],13[0.3176, 0.3294, 0.3451, ..., 0.4431, 0.4431, 0.4392],14[0.3255, 0.3412, 0.3686, ..., 0.4588, 0.4549, 0.4549]],1516[[0.4549, 0.3569, 0.3255, ..., 0.8392, 0.8314, 0.8392],17[0.5569, 0.5451, 0.6667, ..., 0.8039, 0.8196, 0.8431],18[0.7176, 0.5725, 0.6157, ..., 0.4431, 0.5137, 0.5882],19...,20[0.1608, 0.1529, 0.1490, ..., 0.2627, 0.2706, 0.2667],21[0.1569, 0.1608, 0.1686, ..., 0.3059, 0.3137, 0.3176],22[0.1647, 0.1765, 0.1961, ..., 0.3216, 0.3294, 0.3373]]]],23device='cuda:0')24output:tensor([[-0.0901, -0.0180, -0.0841, -0.0019, -0.0262, 0.0122, 0.0764, -0.0555,28-0.1008, 0.0215]], device='cuda:0', grad_fn=<AddmmBackward>)31input:tensor([[[[0.2078, 0.2118, 0.2196, ..., 0.1843, 0.1608, 0.0941],32[0.1804, 0.2078, 0.2118, ..., 0.1647, 0.1529, 0.1098],33[0.1765, 0.1961, 0.1804, ..., 0.1490, 0.1412, 0.1137],34...,35[0.2784, 0.2902, 0.3137, ..., 0.2000, 0.1804, 0.1922],36[0.2941, 0.3098, 0.3176, ..., 0.2392, 0.2510, 0.1882],37[0.3333, 0.3333, 0.3373, ..., 0.2392, 0.2510, 0.1922]],38[[0.2549, 0.2471, 0.2353, ..., 0.2000, 0.1765, 0.1098],39[0.2314, 0.2431, 0.2314, ..., 0.1804, 0.1686, 0.1255],40[0.2314, 0.2353, 0.2039, ..., 0.1647, 0.1569, 0.1294],41...,42[0.3255, 0.3255, 0.3333, ..., 0.2118, 0.1922, 0.1961],43[0.3216, 0.3333, 0.3333, ..., 0.2549, 0.2627, 0.1961],44[0.3255, 0.3294, 0.3373, ..., 0.2549, 0.2627, 0.1961]],4546[[0.2078, 0.2039, 0.1961, ..., 0.1961, 0.1725, 0.1059],47[0.1608, 0.1765, 0.1725, ..., 0.1765, 0.1647, 0.1216],48[0.1490, 0.1608, 0.1333, ..., 0.1608, 0.1529, 0.1255],49...,50[0.2588, 0.2588, 0.2627, ..., 0.1294, 0.1333, 0.1608],51[0.2627, 0.2706, 0.2627, ..., 0.1608, 0.1882, 0.1608],52[0.2784, 0.2784, 0.2745, ..., 0.1529, 0.1804, 0.1608]]]],53device='cuda:0')54output:tensor([[-0.0976, -0.0103, -0.0822, 0.0017, -0.0279, 0.0037, 0.0714, -0.0533,59-0.0968, 0.0251]], device='cuda:0', grad_fn=<AddmmBackward>)
三个迭代中输入相差很大,输出相差无几,还没找到原因,在不同的卡上run的结果都是一样的,现在把代码留下来记录一下:
16012import os3import torch4import torch.nn as nn5import torch.nn.functional as F6import torchvision7import torchvision.transforms as transforms8import torch.optim as optim9from torchsummary import summary10from tensorboardX import SummaryWriter11from torch.autograd import Variable121314# 定义全局变量15modelPath = './model_big.pkl'16batchSize = 6417nEpochs = 5018numPrint = 119writer = SummaryWriter('./logs')20os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"21os.environ["CUDA_VISIBLE_DEVICES"] = "5"22device = torch.device("cuda:0")23file = "logs.txt"24# 加载数据集 (训练集和测试集)25train_transform = transforms.Compose([transforms.Resize((70, 70)),26 transforms.RandomCrop((32, 32)),27 transforms.ToTensor()])2829test_transform = transforms.Compose([transforms.Resize((70, 70)),30 transforms.CenterCrop((32, 32)),31 transforms.ToTensor()])32trainset = torchvision.datasets.CIFAR10(root='./Cifar-10', train=True, download=True, transform=train_transform)33trainloader = torch.utils.data.DataLoader(trainset, batch_size=batchSize, shuffle=True)34testset = torchvision.datasets.CIFAR10(root='./Cifar-10', train=False, download=True, transform=test_transform)35testloader = torch.utils.data.DataLoader(testset, batch_size=batchSize, shuffle=False)36class Flatten(nn.Module):37 def __init__(self):38 super(Flatten,self).__init__()39 40 def forward(self,input):41 shape = torch.prod(torch.tensor(x.shape[1:])).item()42 # -1 把第一个维度保持住43 return x.view(-1,shape)44class Net(nn.Module): # 训练 ALexNet45 '''46 三层卷积,三层全连接 (应该是5层卷积,由于图片是 32 * 32,且为了效率,这里设成了 3 层)47 ''' 48 def __init__(self):49 super(Net, self).__init__()50 self.conv1 = nn.Sequential( # 输入 32 * 32 * 351 nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=1, padding=1), 52 nn.ReLU(),53 nn.Conv2d(in_channels=96, out_channels=96, kernel_size=11, stride=1, padding=1), 54 nn.ReLU(),55 nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # (None, 4, 4, 96)56 )57 self.conv2 = nn.Sequential(58 nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=1), 59 nn.ReLU(),60 nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # (None, 2, 2, 256) 61 )62 self.conv3 = nn.Sequential(63 nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1), 64 nn.ReLU(),65 nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1), 66 nn.ReLU(),# (None, 2, 2, 384) 67 nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1), 68 nn.ReLU(),# (None, 2, 2, 256) 69 nn.MaxPool2d(kernel_size=3, stride=2, padding=1) #(None, 1, 1, 256) 70 )71 self.dense = nn.Sequential(72 #input (4,256)73 nn.Linear(256 * 2 * 2, 4096),74 nn.ReLU(inplace=True),75 nn.Dropout(0.5),76 nn.Linear(4096, 4096),77 nn.ReLU(inplace=True),78 nn.Dropout(0.5),79 nn.Linear(4096, 10),80 )81 def forward(self, x):82 x = self.conv1(x)83 x = self.conv2(x)84 x = self.conv3(x)85 # print("before:",x.shape)86 x = x.view(x.size(0), -1)87 # print(x.shape)88 x = self.dense(x)89 probas = F.softmax(x, dim=1)90 return probas91net = Net().to(device)92summary(net,input_size=(3,32,32))93# if __name__ == '__main__':94# net = Net()95# data_input = Variable(torch.randn([1, 3, 32, 32])) # 这里假设输入图片是96x9696# data = net(data_input)97# print(data)9899# 使用测试数据测试网络100def Accuracy():101 correct = 0102 total = 0103 #matrix output all same104 with torch.no_grad(): # 训练集中不需要反向传播105 for data in testloader:106 images, labels = data107 images, labels = images.to(device), labels.to(device) # 将输入和目标在每一步都送入GPU108 outputs = net(images)109 # print("label",labels," our: ",outputs)110 _, predicted = torch.max(outputs.data, 1) # 返回每一行中最大值的那个元素,且返回其索引111 total += labels.size(0)112 correct += (predicted == labels).sum().item()113 print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))114 return 100.0 * correct / total115116# 训练函数117def train():118 # 定义损失函数和优化器119 criterion = nn.CrossEntropyLoss() # 交叉熵损失120 optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 随机梯度下降121 # optimizer = optim.Adam(net.parameters(), lr=0.001, betas=(0.9, 0.99))122123 iter = 0124 num = 1125 # 训练网络126 for epoch in range(nEpochs): # loop over the dataset multiple times127 running_loss = 0.0128 for i, data in enumerate(trainloader, 0):129 iter = iter + 1130 # 取数据131 inputs, labels = data132 inputs, labels = inputs.to(device), labels.to(device) # 将输入和目标在每一步都送入GPU133 # 将梯度置零134 optimizer.zero_grad()135 # 训练136 outputs = net(inputs)137 loss = criterion(outputs, labels).to(device)138 loss.backward() # 反向传播139 optimizer.step() # 优化140 # 统计数据141 running_loss += loss.item()142 with open(file,'a+') as f:143 f.write('epoch: %d\t batch: %d\t loss: %.6f' % (epoch + 1, i + 1, running_loss / (batchSize*numPrint))) # 每 batchsize * numPrint 张图片,打印一次144 running_loss = 0.0145 writer.add_scalar('accuracy', Accuracy(), num + 1)146 num = num + 1147 # 保存模型148 torch.save(net, './model_big.pkl')149if __name__ == '__main__':150 # 如果模型存在,加载模型151 if os.path.exists(modelPath):152 print('model exits')153 net = torch.load(modelPath)154 print('model loaded')155 else:156 print('model not exits')157 print('Training Started')158 train()159 writer.close()160 print('Training Finished')