Inception block
from GoogLenet
Author:张一极 2020-0321-20:27
谷歌的inceptionnet通过不一样的叠加方法,获取了更深层次的图像特征和语义信息,也为了更高效的利用资源,获取更有利的结果。
两个特点,从inception模块中,第一个是使用1x1卷积降维,第二个特点是,多尺度卷积同时聚合,
使用1x1卷积,可以在卷积过程中,将乘法变为加法,原先堆叠的程度,变成线性的串联,累加起来的计算量,比起直接累乘要少很多。
多通道卷积的优势:
在多个尺寸卷积的情况下,可以获取不同感受野下的不同信息,以往的网络都是3x3的卷积提取特征,inception使用多个通道,1x1,3x3,5x5,组合成一样的特征数目,减少了冗余杂乱,最终的计算效率是一样的,并且收敛速度上更有优势。
所以,我理解的inception结构就是在多个尺度上,进行卷积和池化以后,通过特征通道上的连接给到网络的。
接下来每一个path的结构参考paper给出的结构,
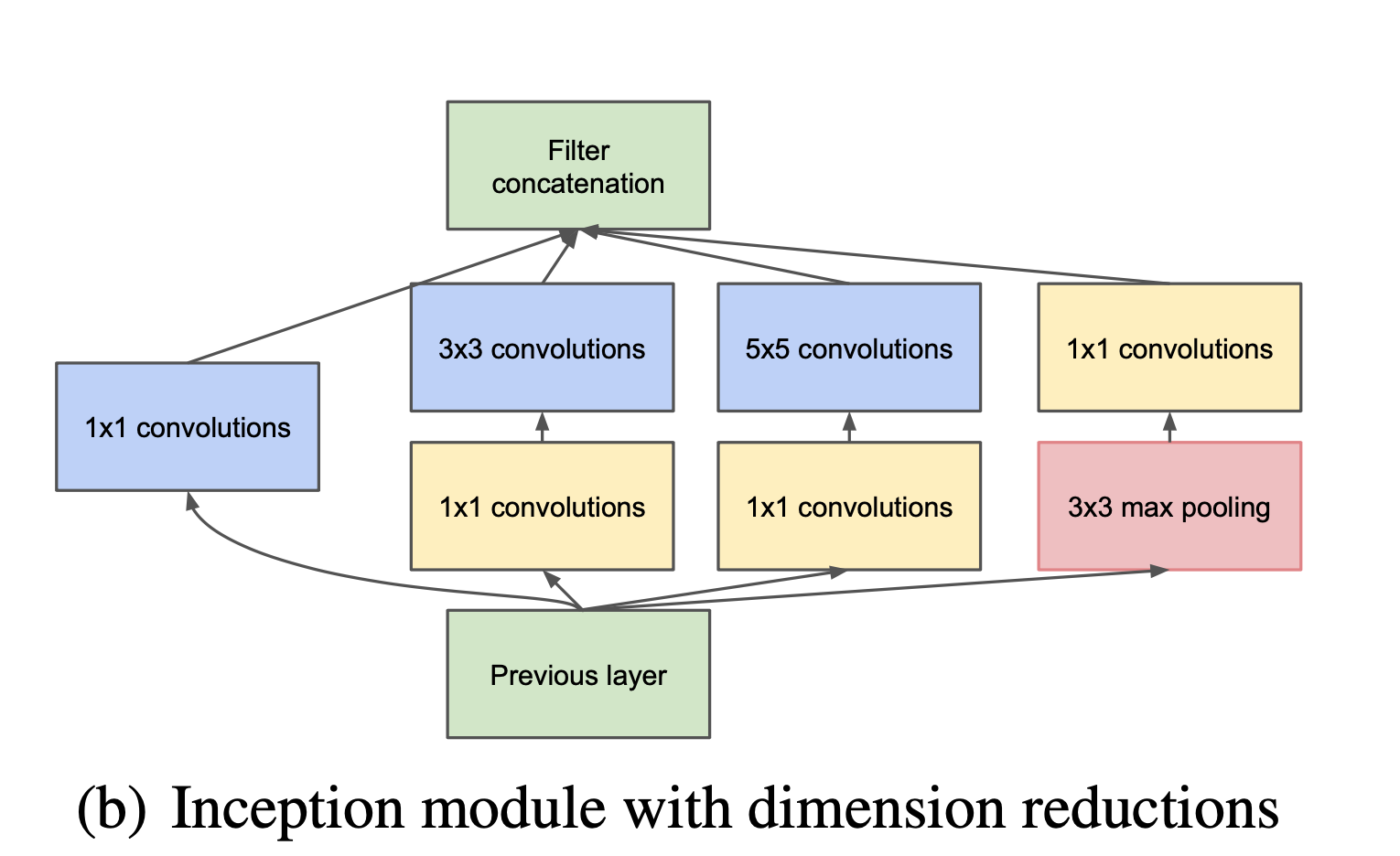
第一条通路,直接经过一个1x1的卷积结构,即上文所述可以在卷积过程中,将乘法变为加法,原先堆叠的程度,变成线性的串联,累加起来的计算量比起直接累乘要少,而作者在论文中提到了,提高深度学习网络效率的一个方法就是增大网络宽度,也就是神经元的个数,但是由此会引起的问题就是关于训练的难题,会导致这些网络结构无法顺利收敛,很多参数收敛到最后都趋于0,浪费了计算机的计算能力,于是论文使用了多个通路,分别是1x1,3x3,5x5的卷积结构,为了方便叠加,无其他的架构,在5x5和3x3之前使用1x1卷积进行降维,防止计算开销过大的问题。
第二条通路,尺度为1的卷积降维+3x3的卷积提取特征,最终输出维度和直接使用3x3的卷积是一样的特征维度。
第三条通道类似,第四条,先是用了一个池化层,一个3x3的maxpooling,但是移动步长为1,这一点很重要,没有减少特征尺寸的情况下,提取了一些图像特征。
Code:
所有的inception模块结构都是一样的,实现了多层通路:
xxxxxxxxxx1231class inception(nn.Module):2 def __init__(self,input_channel,output_channel_1,output_channel2_1,output_channel2_2,output_channel3_1,output_channel3_2,output_channel4_1):3 super(inception,self).__init__()4 self.path_1 = conv_(input_channel,output_channel_1,kernel_size = 1)5 self.path_2 = nn.Sequential(6 conv_(input_channel,output_channel2_1,kernel_size = 1),7 conv_(output_channel2_1,output_channel2_2,kernel_size = 3,padding=1)8 )9 self.path_3 = nn.Sequential(10 conv_(input_channel,output_channel3_1,kernel_size = 1),11 conv_(output_channel3_1,output_channel3_2,kernel_size = 5,padding=2)12 )13 self.path_4 = nn.Sequential(14 nn.MaxPool2d(3,stride = 1,padding = 1),15 conv_(input_channel,output_channel4_1,kernel_size = 1)16 )17 def forward(self,x):18 output_1 = self.path_1(x)19 output_2 = self.path_2(x)20 output_3 = self.path_3(x)21 output_4 = self.path_4(x)22 result_output = torch.cat((output_1,output_2,output_3,output_4),dim = 1)23 return result_output其中conv_函数是一个生成函数,生成一个自定义通道和kernel—size的卷积层:
xxxxxxxxxx1def conv_(in_channel,output_channel,kernel_size,stride = 1,padding = 0):2 layer = nn.Sequential(3 nn.Conv2d(in_channel,output_channel,kernel_size,stride,padding)4 nn.BathNorm2d(output_channel,eps = 1e-3)5 nn.ReLU(True)6 )每一个conv生成的包含三个结构,标准的卷积格式。
网络架构:
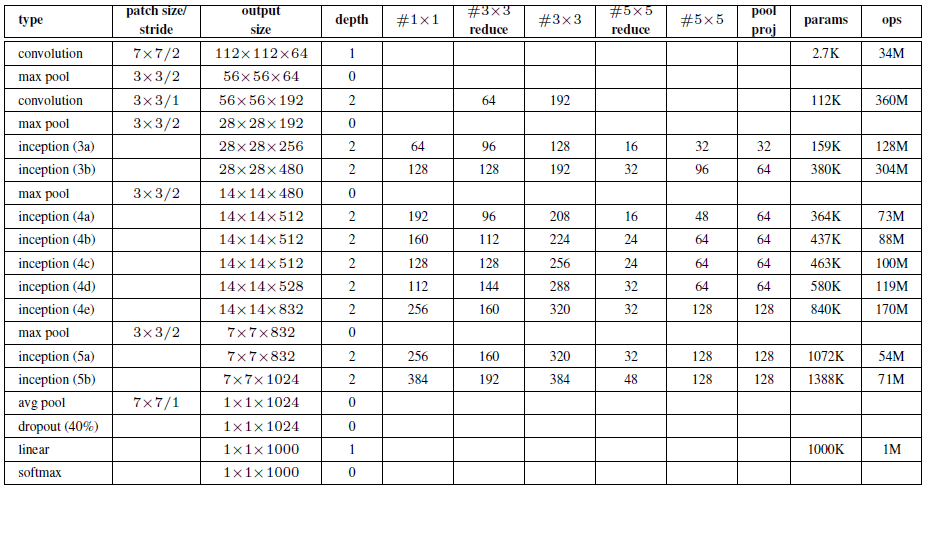
头部网络:
41self.head_block = nn.Sequential(2 conv_(input_channel,output_channel = 64,kernel_size = 7,padding = 3),3 nn.MaxPool2d(3,2)4 )neckblock:
51self.neck_layers = nn.Sequential(2 conv_(64,64,kernel_size = 1),3 conv_(64,output_channel = 192,kernel_size = 3,padding = 1),4 nn.MaxPool2d(3,2)5 )网络结构表格中#3x3表示,先通过1x1卷积,再进入的3x3卷积,所以我们的neckblock多了一个1x1的同输入输出结构,至此,我们实现到了第二个部分,输出维度是28x28x192,下面是第一个inceptions模块。
51self.inception1 = nn.Sequential(2 inception(192,64,96,128,16,32,32),3 inception(256,128,128,192,32,96,64),4 nn.MaxPool2d(3,2)5 )这部分结构,第一个inception,输出是28 *28 * 256,承接它的是第二个的输入,第二个输出是480维度的特征,
21第一个inception:64+32+32+128=2562第二个inception:128+96+64+192=480第二个inceptions:
x101self.inception2 = nn.Sequential(2inception(480,192, 96, 208, 16, 48, 64),3#192+208+48+64=5124inception(512, 160, 112, 224, 24, 64, 64),5#160+224+64+64=5126inception(512, 128, 128, 256, 24, 64, 64),7#128+256+64+64=5128inception(512, 112, 144, 288, 32, 64, 64),9#112+288+64+64=52810inception(528, 256, 160, 320, 32, 128, 128),11#256+320+128+128=83212nn.MaxPool2d(3, 2)13)14
inception操作之后,通过一个maxpooling,size是3的stride=2的池化操作,把输出特征图尺寸降低到了7x7x832,(原来是14x14x832)。
最后一个inception结构:
xxxxxxxxxx11self.inception3 = nn.Sequential(2inception(832, 256, 160, 320, 32, 128, 128),3inception(832, 384, 182, 384, 48, 128, 128),4nn.AvgPool2d(1)5)
使用了avgpooling模块,全局平均池化,论文实验说比全连接层好了0.6个点,所以我也打算做个实验看看可不可行。
Code:
xxxxxxxxxx1 self.last_linear_layer = nn.Linear(1024, num_classes)最后一层linear。
对应的,我做了一组对比实验:
最后一层取代了avg结构:
21self._linear = nn.Linear(36864,1024)2 self.last_linear_layer = nn.Linear(1024, num_classes)All code:
xxxxxxxxxx1import os2import time3import numpy as np4import pandas as pd5import torch6import torch.nn as nn7from torchsummary import summary8from torch.utils.data import DataLoader9from torchvision import datasets10from torchvision import transforms11import torch.nn.functional as F12from tensorboardX import SummaryWriter13if torch.cuda.is_available():14 torch.backends.cudnn.deterministic = True15train_transforms = transforms.Compose([transforms.Resize((225,225)),16 transforms.RandomCrop((224,224)),17 transforms.ToTensor()])1819test_transforms = transforms.Compose([transforms.Resize((225,225)),20 transforms.CenterCrop((224,224)),21 transforms.ToTensor()])22import torch23Random_seed = 101724Learnning_Rate = 0.00125Batch_size = 3226Num_Epochs = 20027input_size = 64*6428Num_Class = 1029writer = SummaryWriter("./my_google_net/")30os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"31os.environ["CUDA_VISIBLE_DEVICES"] = "5"32DEVICE = torch.device("cuda:5")33GRAYSCALE = True34train_dataset = datasets.CIFAR10(root='./Cifar-10', 35 train=True, 36 transform=train_transforms,37 download=True)3839test_dataset = datasets.CIFAR10(root='./Cifar-10', 40 train=False, 41 transform=test_transforms)424344train_loader = DataLoader(dataset=train_dataset, 45 batch_size=Batch_size, 46 shuffle=True)4748test_loader = DataLoader(dataset=test_dataset, 49 batch_size=Batch_size, 50 shuffle=False)51# Checking the dataset52for images, labels in train_loader: 53 print('Image batch dimensions:', images.shape)54 print('Image label dimensions:', labels.shape)55 break56device = torch.device(DEVICE)57torch.manual_seed(0)5859for epoch in range(2):6061 for batch_idx, (x, y) in enumerate(train_loader):62 63 print('Epoch:', epoch+1, end='')64 print(' | Batch index:', batch_idx, end='')65 print(' | Batch size:', y.size()[0])66 67 x = x.to(device)68 y = y.to(device)69 break70def conv_(in_channel,output_channel,kernel_size,stride = 1,padding = 0):71 layer = nn.Sequential(72 nn.Conv2d(in_channel,output_channel,kernel_size,stride,padding),73 nn.BatchNorm2d(output_channel,eps = 1e-3),74 nn.ReLU(True)75 )76 return layer77class inception(nn.Module):78 def __init__(self,input_channel,output_channel_1,output_channel2_1,output_channel2_2,output_channel3_1,output_channel3_2,output_channel4_1):79 super(inception,self).__init__()80 self.path_1 = conv_(input_channel,output_channel_1,kernel_size = 1)81 self.path_2 = nn.Sequential(82 conv_(input_channel,output_channel2_1,kernel_size = 1),83 conv_(output_channel2_1,output_channel2_2,kernel_size = 3,padding=1)84 )85 self.path_3 = nn.Sequential(86 conv_(input_channel,output_channel3_1,kernel_size = 1),87 conv_(output_channel3_1,output_channel3_2,kernel_size = 5,padding=2)88 )89 self.path_4 = nn.Sequential(90 nn.MaxPool2d(3,stride = 1,padding = 1),91 conv_(input_channel,output_channel4_1,kernel_size = 1)92 )93 def forward(self,x):94 output_1 = self.path_1(x)95 output_2 = self.path_2(x)96 output_3 = self.path_3(x)97 output_4 = self.path_4(x)98 result_output = torch.cat((output_1,output_2,output_3,output_4),dim = 1)99 return result_output100class inception_net(nn.Module):101 def __init__(self,input_channel,num_classes):102 super(inception_net,self).__init__()103 self.head_block = nn.Sequential(104 conv_(input_channel,output_channel = 64,kernel_size = 7,padding = 3,stride = 2),105 nn.MaxPool2d(3,2)106 )107 self.neck_layers = nn.Sequential(108 conv_(64,64,kernel_size = 1),109 conv_(64,output_channel = 192,kernel_size = 3,padding = 1),110 nn.MaxPool2d(3,2)111 )112 self.inception1 = nn.Sequential(113 inception(192,64,96,128,16,32,32),114 inception(256,128,128,192,32,96,64),115 nn.MaxPool2d(3,2)116 )117 self.inception2 = nn.Sequential(118 inception(480,192, 96, 208, 16, 48, 64),119 inception(512, 160, 112, 224, 24, 64, 64),120 inception(512, 128, 128, 256, 24, 64, 64),121 inception(512, 112, 144, 288, 32, 64, 64),122 inception(528, 256, 160, 320, 32, 128, 128),123 nn.MaxPool2d(3, 2)124 )125 self.inception3 = nn.Sequential(126 inception(832, 256, 160, 320, 32, 128, 128),127 inception(832, 384, 182, 384, 48, 128, 128),128 # nn.AvgPool2d(1024)129 )130 self._linear = nn.Linear(36864,1024)131 self.last_linear_layer = nn.Linear(1024, num_classes)132 def forward(self, x):133 x = self.head_block(x)134 x = self.neck_layers(x)135 x = self.inception1(x)136 x = self.inception2(x)137 x = self.inception3(x)138 x = x.view(x.shape[0], -1)139 x = self._linear(x)140 logits = self.last_linear_layer(x)141 probas = F.softmax(logits, dim=1)142 return logits, probas143model = inception_net(3,10)144model.to(DEVICE)
实验🧪:going
🏃