Mobilenet深度可分离卷积和多通道卷积梳理
梳理:张一极
2020-04-01-22:51
多通道卷积
输入为3个通道的图像,分为三组分别卷积,乘以一个卷积核,然后将输入的三个通道位置的值,比如说左上角的位置,(0,0,0),就是第一个通道的左上角的3x3的位置(假设kernel_size = 3),如下图:

最终多通道的卷积过程,第一步就是对三个通道都做一遍相应的点乘: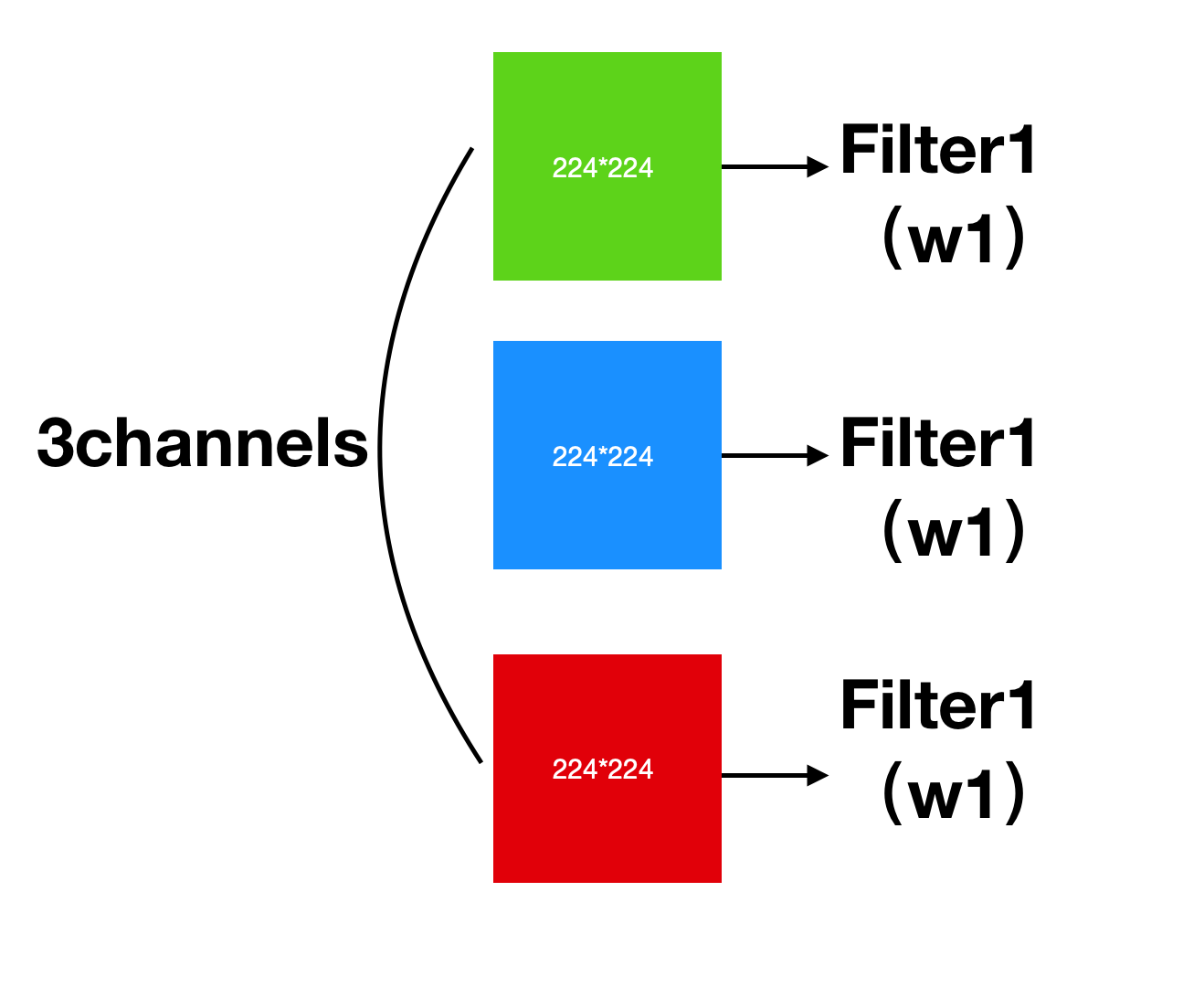
最终的输出:(0,0)点位置的数据为例
两个不同的w,产生两个不同的结果,就是我们所说的输出通道。(n filter = n feature channels)
深度可分离卷积:
深度可分离卷积的过程与传统卷积略有不同,不过基本计算基本相同,分为两步,首先假设输入是224,那么输入矩阵为,第一步提取Depthwise特征(from paper):
将3个通道分组,分别执行3x3卷积,stride = 2,得到的是
filters个输出特征:
这可以当作一个中间变量,这个矩阵的维度和通道数目一致,注意⚠️,是输入图片的通道,接下来是Pointwise特征(from paper)
Pointwise:上一步输入的是和原图一样多的数据图片特征,这一步得到的是最终的结果,和卷积核一样的feature-maps,使用了k个1x1卷积,收集每个poind的特征,mobilenet的深度可分离卷积就是做了这两部份工作,和传统卷积输出特征图尺寸一致。
In this section we first describe the core layers that Mo- bileNet is built on which are depthwise separable filters. We then describe the MobileNet network structure and con- clude with descriptions of the two model shrinking hyper- parameters width multiplier and resolution multiplier.
传统卷积结构和mobilenet的卷积:
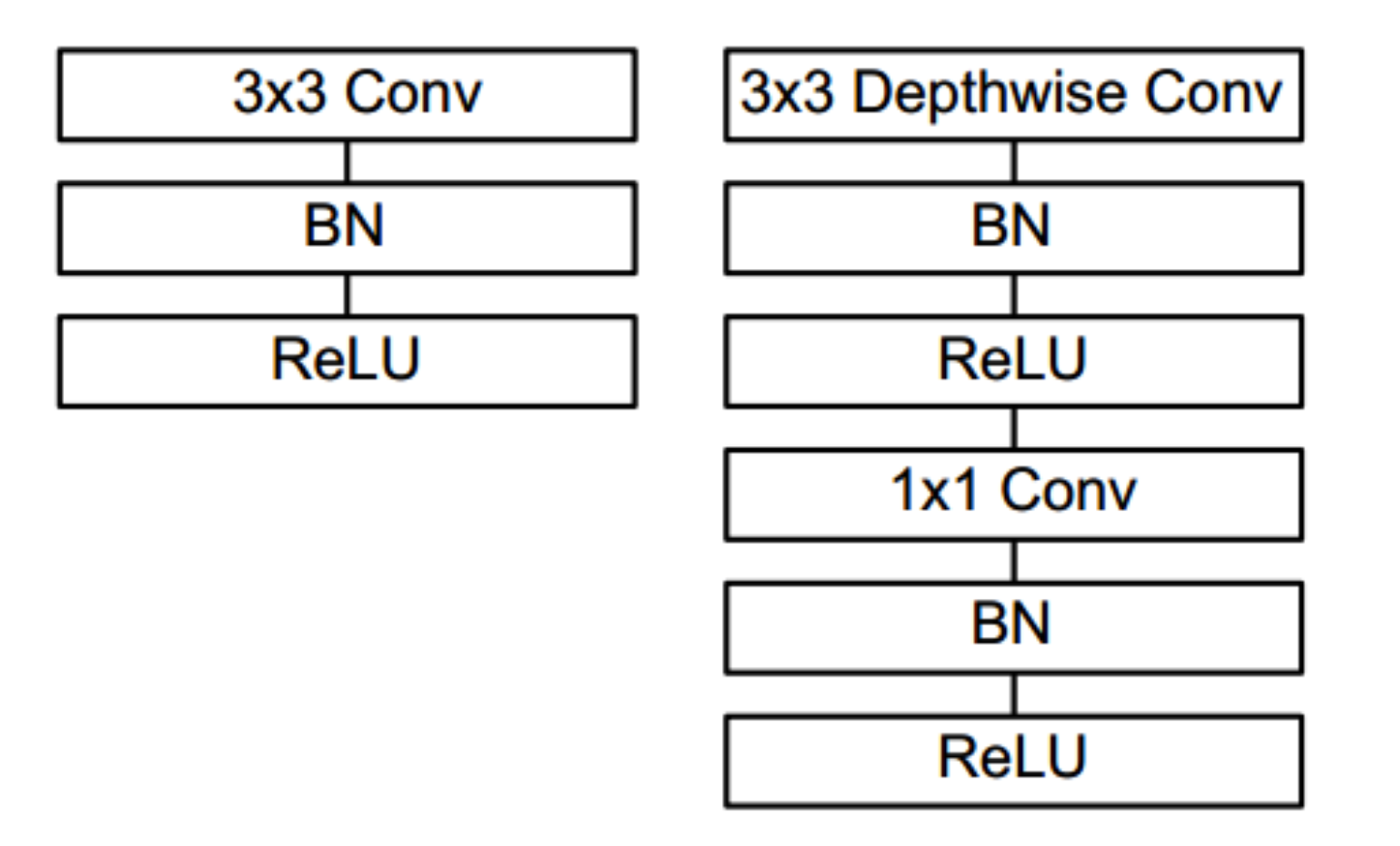
节约计算量的部分:
将传统卷积的多乘操作,拆解为两步相加操作。
可以看出,Depthwise+Pointwise的结构,比起传统卷积,拆解为了两个相加的结构,节省了计算量,最终获得的特征图尺寸是完全一致的。
主体架构细节:
至于作者后期还做了一些工作,将卷积核直接压缩成原来的0.5/0.75等压缩因子alpha的尺寸,进一步缩小计算量:
Mobilenet-v1
541class Block(nn.Module):2 def __init__(self,input_channels, output_channels, stride=1):3 super(Block, self).__init__()4 self.conv1 = nn.Conv2d(input_channels,input_channels,kernel_size=3, stride=stride, 5 padding=1, groups=input_channels, bias=False)6 self.bn1 = nn.BatchNorm2d(input_channels)7 self.conv2 = nn.Conv2d(input_channels, output_channels, kernel_size=1, 8 stride=1, padding=0, bias=False)9 self.bn2 = nn.BatchNorm2d(output_channels)1011 def forward(self, x):12 out = self.conv1(x)13 out = self.bn1(out)14 out = F.relu(out)15 out = self.conv2(out)16 out = self.bn2(out)17 out = F.relu(out)18 return out19class MobileNet(nn.Module):20 def __init__(self,config=[64, (128,2), 128, (256,2), 256, (512,2), 21 512, 512, 512, 512, 512, (1024,2), 1024], num_classes=10):22 self.config = config23 super(MobileNet, self).__init__()24 self.conv1 = nn.Conv2d(3,32,kernel_size=3, 25 stride=1, padding=1, bias=False)26 self.bn1 = nn.BatchNorm2d(32)27 self.layers = self.make_layers(input_channels=32)28 self.linear = nn.Linear(1024, num_classes)2930 def make_layers(self, input_channels):31 layers = []32 for x in self.config:33 if isinstance(x, int):34 output_channels = x 35 stride = 136 else:37 output_channels = x[0]38 stride = x[1]39 layers.append(Block(input_channels,output_channels, stride))40 input_channels = output_channels41 return nn.Sequential(*layers)4243 def forward(self, x):44 x = self.conv1(x)45 x = self.bn1(x)46 x = F.relu(x)47 x = self.layers(x)48 x = F.avg_pool2d(x, 2)49 x = x.view(x.size(0), -1)50 logits = self.linear(x)51 probas = F.softmax(logits, dim=1)52 return logits, probas53model = MobileNet(config = [64, (128,2), 128, (256,2), 256, (512,2), 54 512, 512, 512, 512, 512, (1024,2), 1024])现在实现的部分在cpu上能够跑起来顺利收敛,在多个gpu上调用会出现问题,待解决。
paper:https://arxiv.org/pdf/1704.04861.pdf
我自己尝试的实验记录后续更新~