Why prune or not to prune
Author:张一极
Email:zk@likedge.top
引言
Deploying large, accurate deep learning models to resource-constrained computing environments such as mobile phones, smart cameras etc. for on-device inference poses a few key challenges
以上,便是模型剪枝领域重点关注的问题,即模型精度与模型开销的平衡问题。
Paper:
To prune, or not to prune: exploring the efficacy of pruning for model compression
——from Google
主要优化
模型压缩提出了两部分的优化,一个是内存密集部分的访问量,另外就是提高了获取模型参数的时间,即推理中的加载完毕时间。
主要实验
在模型压缩领域,我们通过清理不显著的连接参数,的确可以减少模型中非0参数的数量,并且不会对模型推理质量造成太大的影响,即使造成了影响,我们也能通过后续的微调调整回来。
文章首先测试了分类模型针对稀疏度的影响:利用tensorflow实现了对inceptionv3的模型剪枝,通过权重mask去遮盖剪枝完的权重,具体方法就是将得到权重在梯度下降的过程中,与mask点乘,屏蔽掉剪枝部分的梯度,不进行训练,同时这个mask会参与到模型的forward中,其中模型稀疏程度,通过下式定义:
其中for
其中
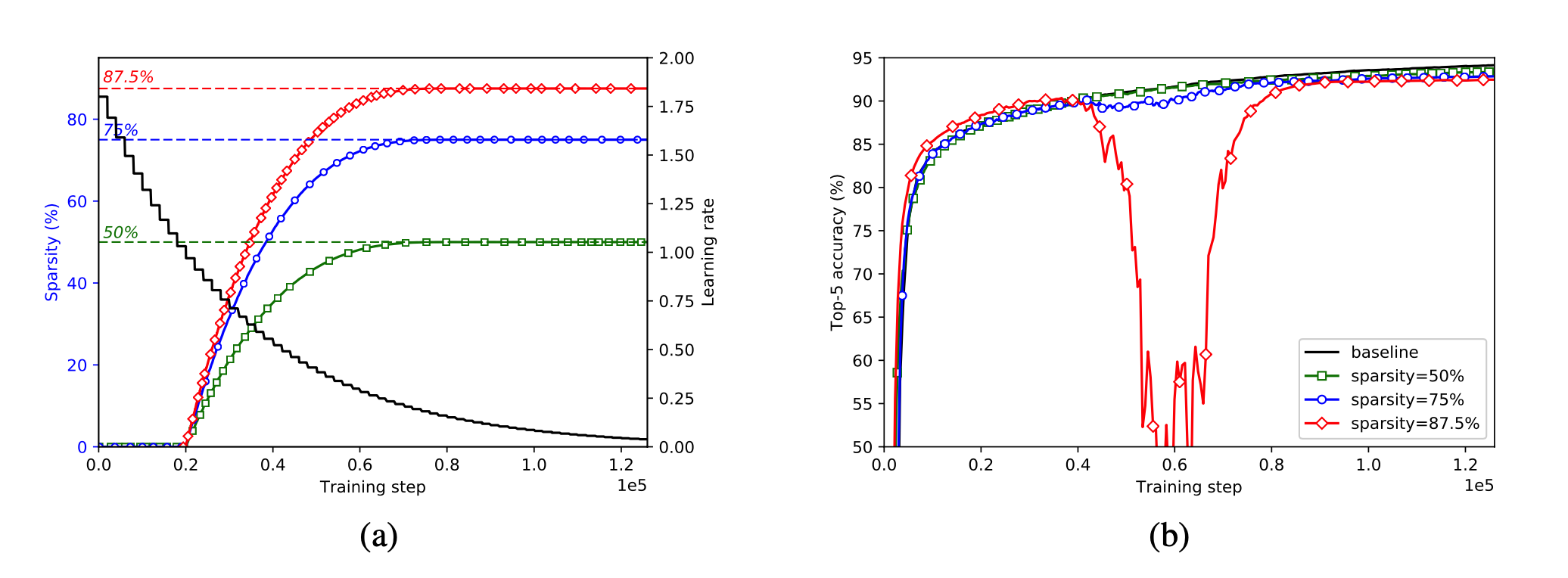
上图b中,分类网络inceptionv3的稀疏性不断提高,在稀疏程度达到87.5%的时候,训练过程中出现了一次准确率大幅下跌的情况,随后几乎以相同的速率,准确率回到了开始水平,此时我们可以推测稀疏掉的部分可能带有一部分核心权重,但是并不会影响到模型的拟合性能。通过微调几个epoch以后仍然能把模型恢复到较高水平,依然有着不低于baseline的拟合能力。
文章观察到修剪一个非常小的学习速率的存在使随后的训练步骤很难恢复精度损失,同时,学习率过高的剪枝可能意味着在权值尚未收敛的情况下将权值删除,所以才要一个与学习率相互影响的剪枝递进比例。
以下,是模型稀疏程度与acc的实验记录。
大而稀疏还是小而紧凑?
为了验证大而稀疏的模型与小而紧凑的模型优劣情况在分类任务下的分布。测试了mobilenet在不同稀疏程度和模型大小的情况下性能表现。
Mobilenet:
LSTM:
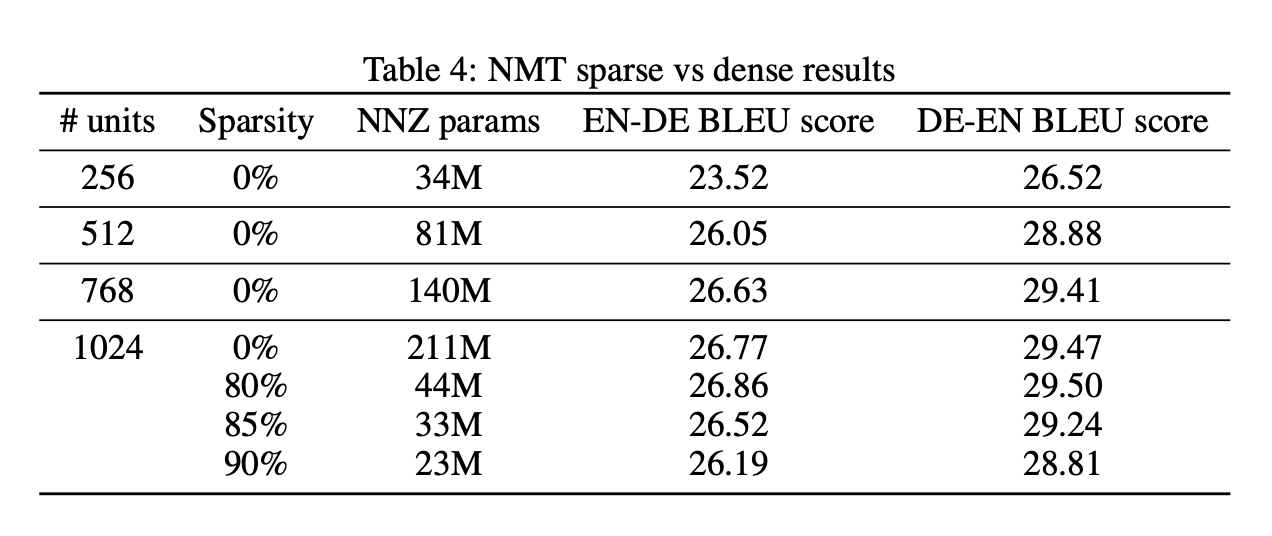
结论:
1.在内存占用相当的情况下,大稀疏模型比小密集模型实现了更高的精度,稀疏程度需要与学习率联动,保证整体流程不造成无法挽回的精度损失。
2.经过剪枝之后的稀疏大模型要优于同体积的非稀疏模型。
3.文中提出的递进剪枝策略可以广泛的应用于不同模型。
4.资源有限的情况下,剪枝是比较有效的模型压缩策略。
5.目前优化点还可以往硬件稀疏矩阵储存方向发展。