Resnet梳理和复盘
整理:张一极 2020·0319·19:44
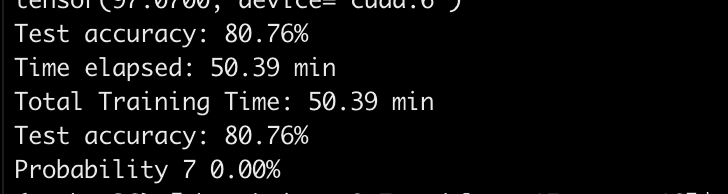
Resnet的跳层连接:
由于过深的网络无法训练的问题,作者将下一层的网络设置为F(x)+ x,不断的叠加之后,可以从第一层,一直堆叠到最后一层,都可以得到有效的训练。
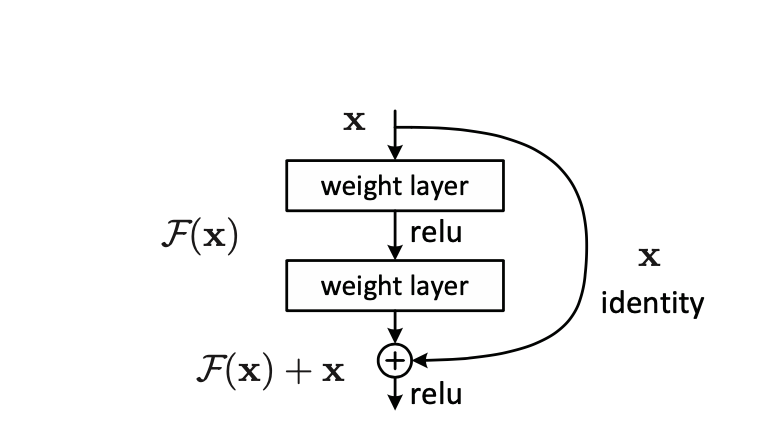
网络结构:
后面三个卷积层组成的网络块和前面最大的区别就是,使用了瓶颈层的结构,小卷积到大卷积再到小卷积,每个网络都是由4个块组成,每个块包含的卷积结构有所不同,但是有共同之处,例如前两个网络结构,18-layer和34-layer,都是由四个块(blocks)组成,每一个块的输入卷积和输出卷积完全一样,这样我们就可以定义一个通用的卷积组合,进行堆叠即可得到不同的网络结构。
解析关于pytorch的实现:
首先写一个函数:
1def conv3x3(input_channel,output_channel,stride = 1):2 return nn.Conv2d(input_channel,output_channel,kernel_size =3,stride=stride,padding =1,bias = False)实现了一个通用的3x3的卷积块,我们用它来构筑3x3的卷积层,其中,bias不设置是因为我们后面有bn层,无需设置偏置去修改修复数据分布位移。
接着就是用这个生成卷积层的函数,去实现基础模块,也就是多个组合的卷积层。
就是这两个层,两个3x3的conv,output_channels = 64:
xxxxxxxxxx231class BasicBlock(nn.Module):2 expansion = 13 def __init__(self,input_channels,output_channels,stride = 1,downsample = None):4 super(BasicBlock,self).__init__()5 self.conv1 = conv3x3(input_channels,output_channels,stride)6 self.bn1 = nn.BatchNorm2d(output_channels)7 self.relu = nn.ReLU(inplace = True)8 self.conv2 = conv3x3(output_channels,output_channels)9 self.bn2 = nn.BatchNorm2d(output_channels)10 self.downsample = downsample11 self.stride = stride12 def forward(self,x):13 residual = x14 output = self.conv1(x)15 output = self.bn1(output)16 output = self.relu(output)17 output = self.conv2(output)18 output = self.bn2(output)19 if self.downsample is not None:20 residual = self.downsample(x)21 output+=residual#residual added22 output = self.relu(output)23 return outputexpansion是扩张系数,对应的构造函数,这时候不用在意构造了什么参数,我们之后慢慢写慢慢往上添加,首先是继承自己的这么一句话,super(BasicBlock,self). init(),接着定义一个输入的卷积层,用构筑好的conv3x3,需求参数就是输入通道数目和输出通道数目,接着使用一个归一化层,然后激活层,很标准的conv格式,接下来是第二层,一样标准的卷积格式,然后没有定义激活层是因为我们后面需要对两个block之间跳层相连,需要在激活层之前进行相加,而后再统一激活,故这里我们没有定义激活层,接下来的downsample是下采样的作用,为了保证跳层之间的维度相融,这时候回过头来,我们既然决定了在这里执行下采样,那么就必须在这里输入下采样函数,所以回到参数部分,加入一个downsample参数,然后我们还需要输入维度和输出维度,前向传播里面,一层一层写完以后,我们需要把激活层之前的输出和残差(输入)做一个叠加操作,这个就是Resnet的add,完整代码,如上。
接下来是函数主体部分,首先, 定义好输入通道,也就是64维的,在网络结构图可以看出,接着一个7x7的卷积,bn,然后relu激活层,接着一个pooling,开始定义第一个网络块,这时候的这个定义块函数,我单独解析一遍:
xxxxxxxxxx131def make_blocks(self,block,outputs,num_blocks,stride = 1):2 downsample = None3 if stride!=1 or self.inputchannel != outputs:4 downsample = nn.Sequential(5 nn.Conv2d(self.inputchannel,outputs,kernel_size = 1,stride=stride,bias = False),6 nn.BatchNorm2d(outputs)7 )8 layers = []9 layers.append(block(self.inputchannel,outputs,stride,downsample))10 self.inputchannel = outputs11 for i in range(1,num_blocks):12 layers.append(block(self.inputchannel,outputs))13 return nn.Sequential(*layers)这个downsample函数,定义为一个序列函数,包含一个1x1的卷积和bn,用于改变矩阵的通道数目,至于if的条件,就是我们所说的,通道维度变化的时候,才需要改变通道数目去保证维度相融。
接着建立了一个list,先添加了第一层的参数,第一个块函数,输入通道由函数给定,输出函数也由我们Resnet类给定,至于为什么第一层要单独添加,是因为我们需要在之后把输入通道改成第一层的输出通道,而后是一个循环,循环到最后一个层添加完毕,返回这个list的所有层。
最后,开始搭建网络主体。
下面四行分别代表四大模块:
xxxxxxxxxx41self.layer_one = self.make_blocks(block,64,layers[0])2 self.layer_second = self.make_blocks(block,128,layers[1],stride=2)3 self.layer_third = self.make_blocks(block,256,layers[2],stride=2)4 self.layer_fouth = self.make_blocks(block,512,layers[3],stride=2)Resnet类的主体代码:
xxxxxxxxxx401class Resnet(nn.Module):2 def __init__(self,input_dim,inputchannel,block,layers):3 self.inputchannel = 644 super(Resnet,self).__init__()5 self.conv1 = nn.Conv2d(input_dim,64,kernel_size = 7,stride = 2,padding = 3,bias = False)6 self.bn1 = nn.BatchNorm2d(64)7 self.relu = nn.ReLU(inplace = True)8 self.maxpooling = nn.MaxPool2d(kernel_size = 3,stride = 2,padding = 1)9 self.layer_one = self.make_blocks(block,64,layers[0])10 self.layer_second = self.make_blocks(block,128,layers[1],stride=2)11 self.layer_third = self.make_blocks(block,256,layers[2],stride=2)12 self.layer_fouth = self.make_blocks(block,512,layers[3],stride=2)13 self.avgpool = nn.AvgPool2d(7, stride=1)14 self.fc = nn.Linear(512,10)15 def make_blocks(self,block,outputs,num_blocks,stride = 1):16 downsample = None17 if stride!=1 or self.inputchannel != outputs:18 downsample = nn.Sequential(19 nn.Conv2d(self.inputchannel,outputs,kernel_size = 1,stride=stride,bias = False),20 nn.BatchNorm2d(outputs)21 )22 layers = []23 layers.append(block(self.inputchannel,outputs,stride,downsample))24 self.inputchannel = outputs25 for i in range(1,num_blocks):26 layers.append(block(self.inputchannel,outputs))27 return nn.Sequential(*layers)28 def forward(self, x):29 x = self.conv1(x)30 x = self.bn1(x)31 x = self.relu(x)32 x = self.maxpooling(x)33 x = self.layer_one(x)34 x = self.layer_second(x)35 x = self.layer_third(x)36 x = self.layer_fouth(x)37 x = x.view(x.size(0), -1)38 logits = self.fc(x)39 probas = F.softmax(logits, dim=1)40 return logits, probas前向传播较为简单,一层对着一层写即可,最终卷积层之后flatten成全连接可以接受的维度,输出softmax压缩结果。
完整代码:
x1import os2import time3import numpy as np4import pandas as pd5import torch6import torch.nn as nn7from torchsummary import summary8from torch.utils.data import DataLoader9from torchvision import datasets10from torchvision import transforms11import torch.nn.functional as F12from tensorboardX import SummaryWriter13if torch.cuda.is_available():14 torch.backends.cudnn.deterministic = True15Random_seed = 101716Learnning_Rate = 0.00117Batch_size = 12818Num_Epochs = 1019input_size = 28*2820Num_Class = 1021writer = SummaryWriter("./test/")22DEVICE = "cuda:6"23GRAYSCALE = True24train_dataset = datasets.MNIST(root='data', 25 train=True, 26 transform=transforms.ToTensor(),27 download=True)2829test_dataset = datasets.MNIST(root='data', 30 train=False, 31 transform=transforms.ToTensor())323334train_loader = DataLoader(dataset=train_dataset, 35 batch_size=Batch_size, 36 shuffle=True)3738test_loader = DataLoader(dataset=test_dataset, 39 batch_size=Batch_size, 40 shuffle=False)41device = torch.device(DEVICE)42torch.manual_seed(0)43for epoch in range(2):44 for batch_idx, (x, y) in enumerate(train_loader):45 x = x.to(device)46 y = y.to(device)47 break48def conv3x3(input_channel,output_channel,stride = 1):49 return nn.Conv2d(input_channel,output_channel,kernel_size = 3,stride=stride,padding =1,bias = False)50class BasicBlock(nn.Module):51 expansion = 152 def __init__(self,input_channels,output_channels,stride = 1,downsample = None):53 super(BasicBlock,self).__init__()54 self.conv1 = conv3x3(input_channels,output_channels,stride)55 self.bn1 = nn.BatchNorm2d(output_channels)56 self.relu = nn.ReLU(inplace = True)57 self.conv2 = conv3x3(output_channels,output_channels)58 self.bn2 = nn.BatchNorm2d(output_channels)59 self.downsample = downsample60 self.stride = stride61 def forward(self,x):62 residual = x63 output = self.conv1(x)64 output = self.bn1(output)65 output = self.relu(output)66 output = self.conv2(output)67 output = self.bn2(output)68 if self.downsample is not None:69 residual = self.downsample(x)70 output+=residual#residual added71 output = self.relu(output)72 return output73class Resnet(nn.Module):74 def __init__(self,input_dim,inputchannel,block,layers):75 self.inputchannel = 6476 super(Resnet,self).__init__()77 self.conv1 = nn.Conv2d(input_dim,64,kernel_size = 7,stride = 2,padding = 3,bias = False)78 self.bn1 = nn.BatchNorm2d(64)79 self.relu = nn.ReLU(inplace = True)80 self.maxpooling = nn.MaxPool2d(kernel_size = 3,stride = 2,padding = 1)81 self.layer_one = self.make_blocks(block,64,layers[0])82 self.layer_second = self.make_blocks(block,128,layers[1],stride=2)83 self.layer_third = self.make_blocks(block,256,layers[2],stride=2)84 self.layer_fouth = self.make_blocks(block,512,layers[3],stride=2)85 self.avgpool = nn.AvgPool2d(7, stride=1)86 self.fc = nn.Linear(512,10)87 def make_blocks(self,block,outputs,num_blocks,stride = 1):88 downsample = None89 if stride!=1 or self.inputchannel != outputs:90 downsample = nn.Sequential(91 nn.Conv2d(self.inputchannel,outputs,kernel_size = 1,stride=stride,bias = False),92 nn.BatchNorm2d(outputs)93 )94 layers = []95 layers.append(block(self.inputchannel,outputs,stride,downsample))96 self.inputchannel = outputs97 for i in range(1,num_blocks):98 layers.append(block(self.inputchannel,outputs))99 return nn.Sequential(*layers)100 def forward(self, x):101 x = self.conv1(x)102 x = self.bn1(x)103 x = self.relu(x)104 x = self.maxpooling(x)105 x = self.layer_one(x)106 x = self.layer_second(x)107 x = self.layer_third(x)108 x = self.layer_fouth(x)109 x = x.view(x.size(0), -1)110 logits = self.fc(x)111 probas = F.softmax(logits, dim=1)112 return logits, probas113model = Resnet(input_dim = 1,inputchannel = 64,block = BasicBlock,layers = [2,2,2,2])114summary(model.cuda(), input_size=(1,28,28))115model.to(DEVICE)116optimizer = torch.optim.Adam(model.parameters(),lr = Learnning_Rate)117def compute_accuracy(model, data_loader, device):118 correct_pred, num_examples = 0, 0119 for i, (features, targets) in enumerate(data_loader):120 features = features.to(device)121 targets = targets.to(device)122 logits, probas = model(features)123 _, predicted_labels = torch.max(probas, 1)124 num_examples += targets.size(0)125 correct_pred += (predicted_labels == targets).sum()126 return correct_pred.float()/num_examples * 100127start_time = time.time()128for epoch in range(10):129 model.train()130 for batch_idx, (features, targets) in enumerate(train_loader):131 features = features.to(DEVICE)132 targets = targets.to(DEVICE)133 logits, probas = model(features)134 cost = F.cross_entropy(logits, targets)135 optimizer.zero_grad()136 cost.backward()137 optimizer.step()138 if not batch_idx % 50:139 print ('Epoch: %03d/%03d | Batch %04d/%04d | Cost: %.4f' 140 %(epoch+1,10, batch_idx, 141 len(train_loader), cost))142 writer.add_scalar("batch_Loss",cost,batch_idx)143 writer.add_scalar("epoch_Loss",cost,epoch)144 model.eval()145 writer.add_scalar('val_accuracy',compute_accuracy(model, test_loader, device=DEVICE),epoch)146 writer.add_scalar('train_accuracy',compute_accuracy(model, train_loader, device=DEVICE),epoch)147 with torch.set_grad_enabled(False): # save memory during inference148 print('Epoch: %03d/%03d | Train: %.3f%%' % (149 epoch+1,10, 150 compute_accuracy(model, train_loader, device=DEVICE)))151 print('Time elapsed: %.2f min' % ((time.time() - start_time)/60))152print('Total Training Time: %.2f min' % ((time.time() - start_time)/60))153with torch.set_grad_enabled(False): # save memory during inference154 print('Test accuracy: %.2f%%' % (compute_accuracy(model, test_loader, device=DEVICE)))155for batch_idx, (features, targets) in enumerate(test_loader):156 features = features157 targets = targets158 break159model.eval()160logits, probas = model(features.to(device)[0, None])161print('Probability 7 %.2f%%' % (probas[0][7]*100))结果
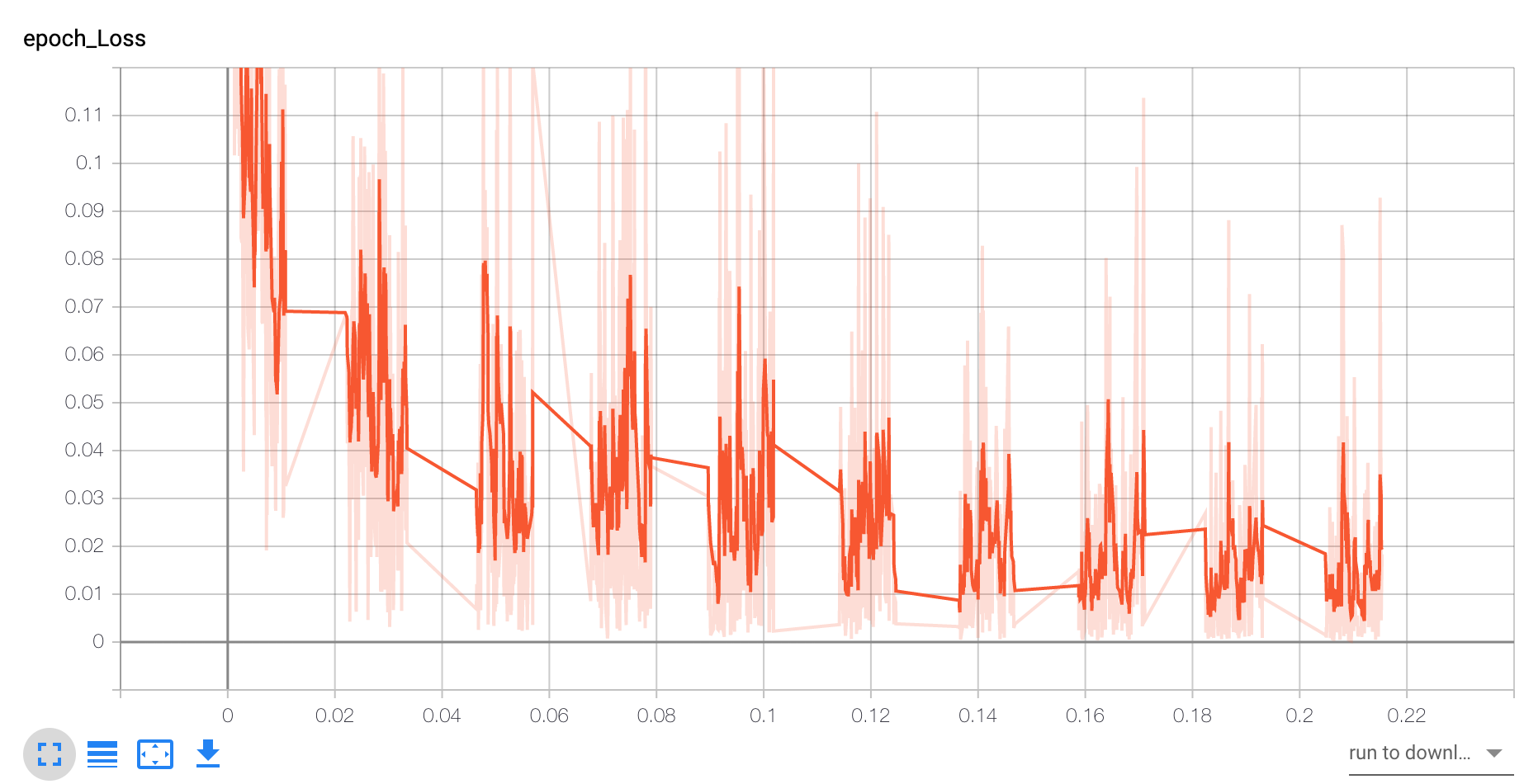 Acc和loss抖动都很大,可能写的比较粗糙了,下次用更复杂的数据实验:
Acc和loss抖动都很大,可能写的比较粗糙了,下次用更复杂的数据实验:
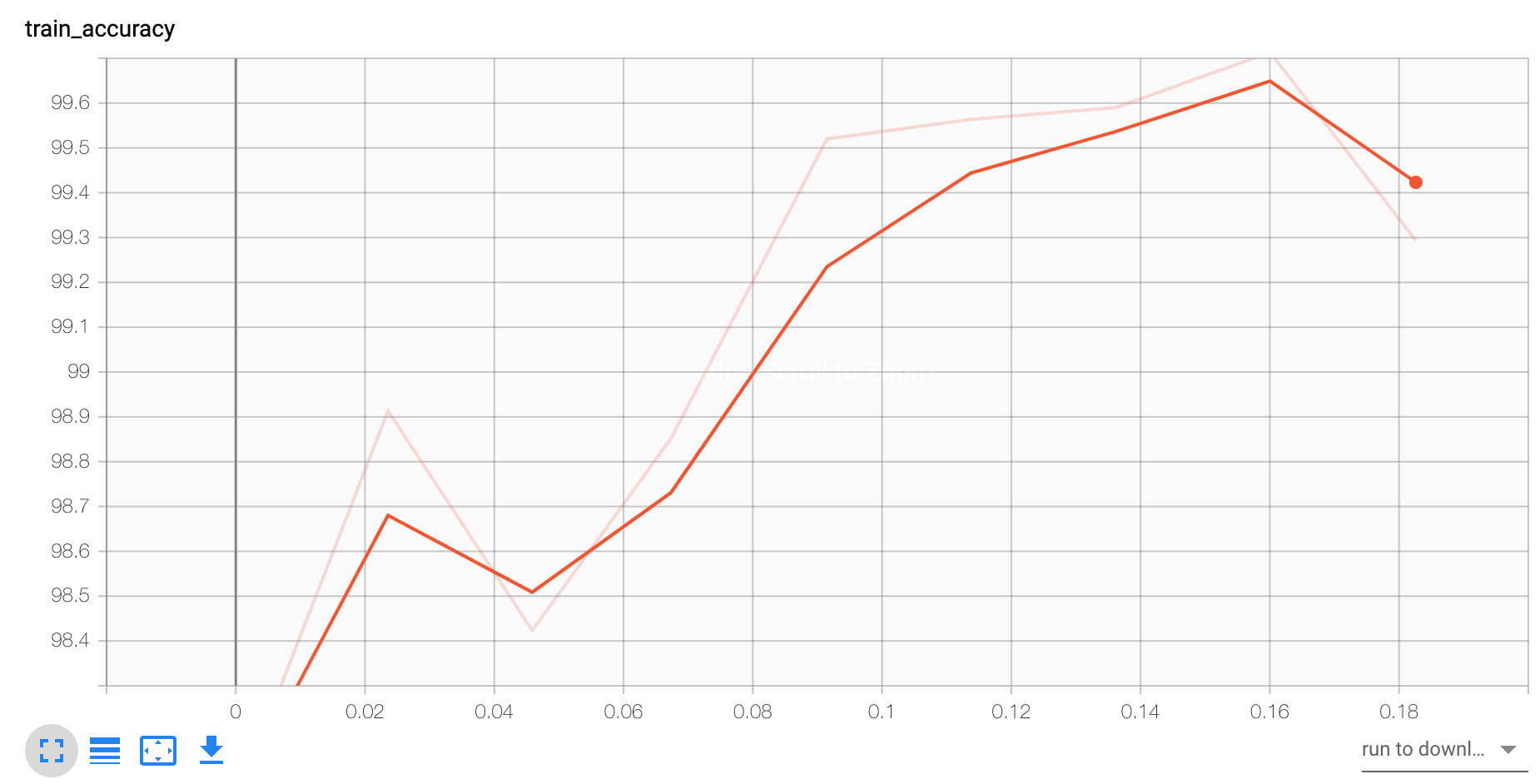
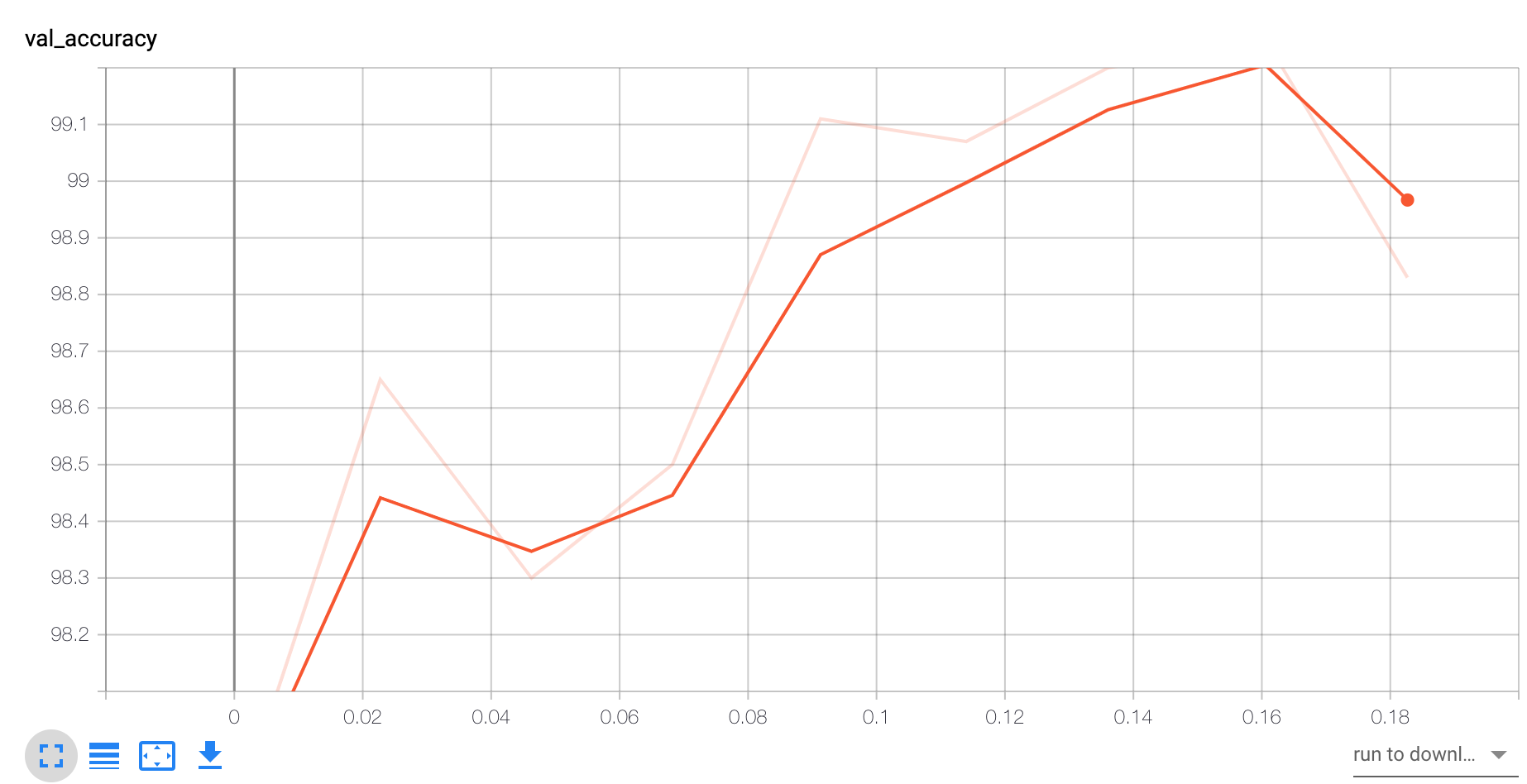
在加入一个策略,图片尺寸resize到较大尺寸之后,随机crop到某个固定尺寸:
有两个点左右的提升