Anomaly Detection
@张一极
zk@likedge.top
关于异常点检测而言,目标就是检测出数据中与大体规律相违背的异常值,用以提高模型性能和表现。
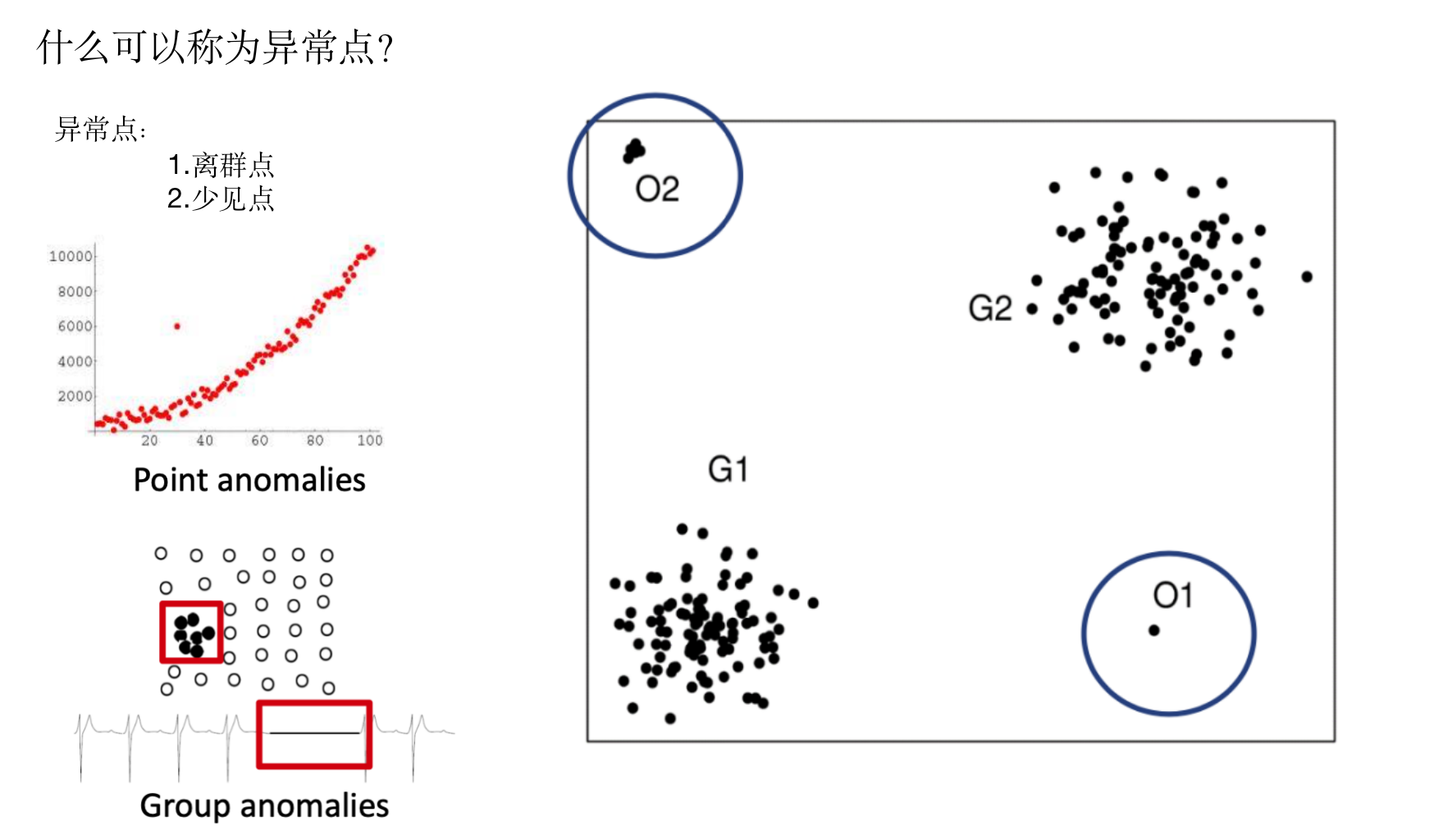
图像领域的异常样本:
图像领域的异常样本我们一般使用将原始数据编码成新数据,再把新数据解码成类似原始数据的结果,得到encode-decode之后的新数据,观察新数据与原生数据,会发现他们比较类似,或具有类似特征,如果异常样本输入以后,我们解码出的图像也会趋近于正常样本(编码器解码器的参数固定),进行比对可得到其是否为异常样本以及发生异常的位置,即异常区域。
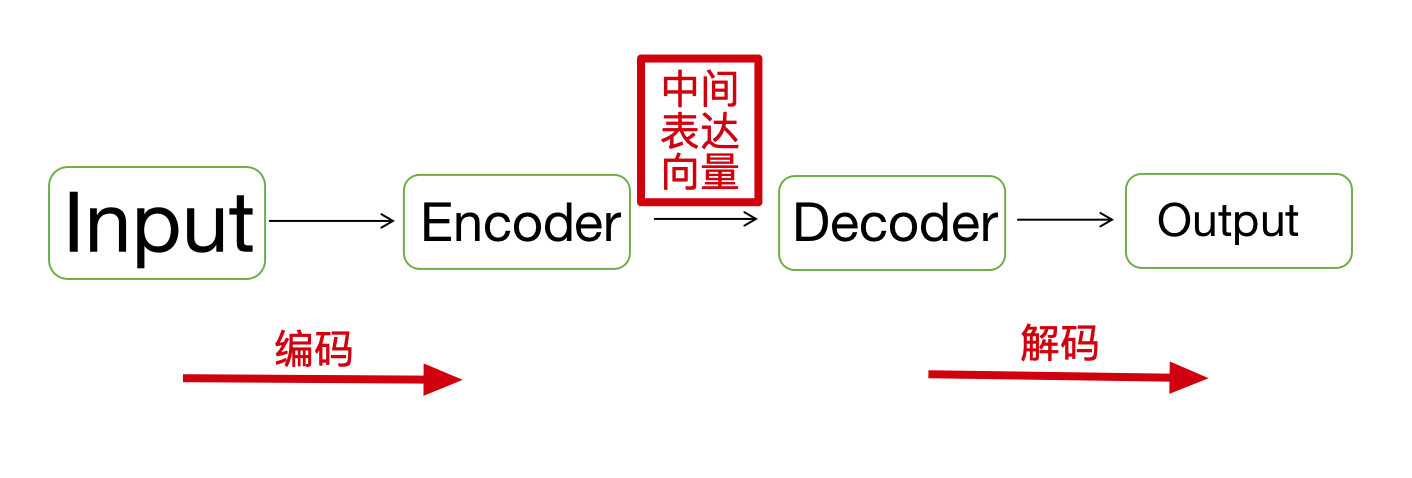
通过编码器解码器之后的部分,会刷新整个图像的特征表达。
如果出现了异常样本,那么通过正常样本训练出的编码器和解码器处理的异常样本,会体现正常样本的特征,就可以通过比对进行剔除。
但是按照我们对模型的理解,拟合总是不完美的,且有一定的泛化性能,会不自觉地抹除掉一些异常特征维度,所以我们需要抑制这部分泛化性能,将编码解码作为一个固定参数的函数去实现,防止泛化,之前为了提高模型泛化性能,一般会引入之前的特征作为输入的一条支路(Resnet),而关于编码解码的实现,却不能说简单的把前面模型输入作为支路输入,因为异常样本裹挟了异常特征输入,无法筛选,所以可以使用全局的正常样本做一个加权平均,即每一个正常样本的embedding都保存到一个地方,每一次输入一个新的数据,都将进入这个地方,把现有的emebdding去做一一比对,计算余弦相似度,通过余弦相似度作为权重,组合正常样本的embedding输出为新数据的解码结果,这时候,我们会发现,不管输入的是正常样本或异常样本,都会从正常样本中挑选出向量进行加权组合,权重即正常样本中与现比较数据的相似度,确保了以正常样本为空间的组合方式,抑制了模型泛化出异常特征的能力。
如下:
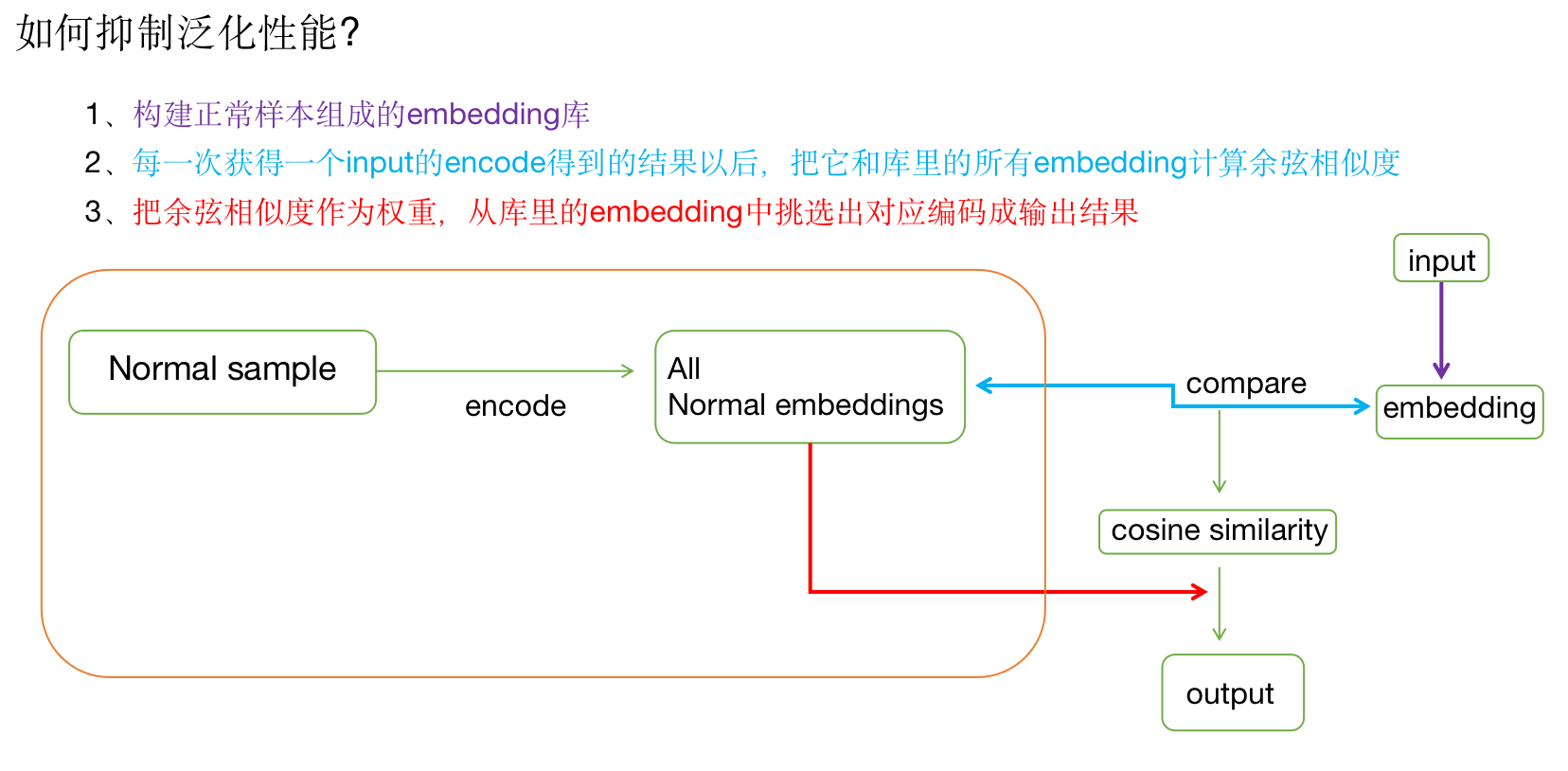
细节:
1、关于权重的计算:
两个embedding的余弦值可以通过欧几里得点积得到:,a和b的余弦为
paper中的embedding需要做一个转置,方便点积,,输入embedding为,为库中第i个向量。
2、关于embedding个数的限制
,为使其可导,
权重计算后,将权重与embedding库中的数据组合为最后结果。
GAN
使用到了图像重建,自然有GAN的用武之地
- 用generator重构图像,discriminator只是用来帮助generator更好地重构图像。在判断异常时,类似于auto-encoder检测异常的思路,用generator重构后的图像和原图做对比,不同处认为是异常;
- 使用gan重建图像,在检测异常时,综合generator和discriminator的结果作为判断异常的依据。
Old is Gold: Redefining the Adversarially Learned One-Class Classifier Training Paradigm
这篇paper中讲述了gan在异常检测的无监督做法,最后分类网络的输入分为多个,有精细的gan输出,有较为粗糙的gan输出,还有原图,最后综合判断,比较与原图的区别,分类出是否为异常样本。
细节:
一般训练gan,首先固定generator, 只更新discriminator的参数。从你准备的数据集中随机选择一些,再从generator的output中选择一些,现在等于discriminator有两种input。
接下来, discriminator的学习目标是, 如果输入是来自于真实数据集,则给高分;如果是generator产生的数据,则给低分,可以把它当做一个回归问题。 接下来,固定住discriminator的参数, 更新generator。将一个向量输入generator, 得到一个output, 将output扔进discriminator, 然后会得到一个分数,这一阶段discriminator的参数已经固定住了,generator需要调整自己的参数使得这个output的分数越大越好。
异常检测领域,使用gan重构图像以后同样设置一个判别器来判断图像是原图还是重构的图像,这里训练gan使用两个不同深度的训练结果,一个是较为精细效果较好的深训练模型,一个是较为粗糙效果一般的浅层模型,浅层模型用以构建粗糙结果,深层模型构建精确结果,配合文章提出的一个异常样本生成方法(随机组合两张图像,以像素平均的方式组合),再输入到生成网络里面得到重构图像的异常样本。
这里的判别器需要判断是高质量重构图像、原图,还是低质量重构图像、或用像素平均方法生成的异常样本,如下
另:teacher-students交替训练做异常检测
首先,在正常样本上输出一个teacher网络,用以调节student网络的参数,具体做法是在正常数据进行pretrain,得到teacher模型,让student的输出embedding和teacher的输出越接近越好。
接着,我们就会发现因为student只知道怎么embed正常的数据,所以输入为异常数据的时候,他和teacher的输出差异会比较大,用以实现异常检测。
如果1当中训练过程,采用多个随机初始化的模型,配合一个只在正常样本上pretrain过的teacher模型,多个student模型对同一个正常样本的embedding是大致相似的,因为有teacher模型帮助他们去做embed,对应的,在异常样本上的embedding,就没有teacher教他们应该怎么去表达,由于他们是随机初始化的结果,最后的embedding一定有所差异,所以可以判断出异常样本。